

Explicación: ¿Cómo la regularización L1 selecciona automáticamente las características?
Comprenda el proceso de selección automática de características realizado por la regularización L1 (LASSO).
La selección de características es el proceso de seleccionar un subconjunto óptimo de características de un conjunto dado de características; El subconjunto óptimo es el que maximiza el rendimiento del modelo en la tarea dada.
La identificación de características puede ser un proceso manual o más bien explícito cuando se realiza mediante métodos de filtro o métodos envolventes. En estos métodos, las características se agregan o eliminan iterativamente en función del valor de una métrica fija, que determina la importancia de la característica para realizar una predicción. Las métricas pueden ser ganancia de información, varianza o estadística de chi-cuadrado, y el algoritmo tomará una decisión de aceptar o rechazar la característica considerando un umbral fijo en la métrica. Cabe señalar que estos métodos no forman parte de la fase de entrenamiento del modelo y se realizan antes de ella.
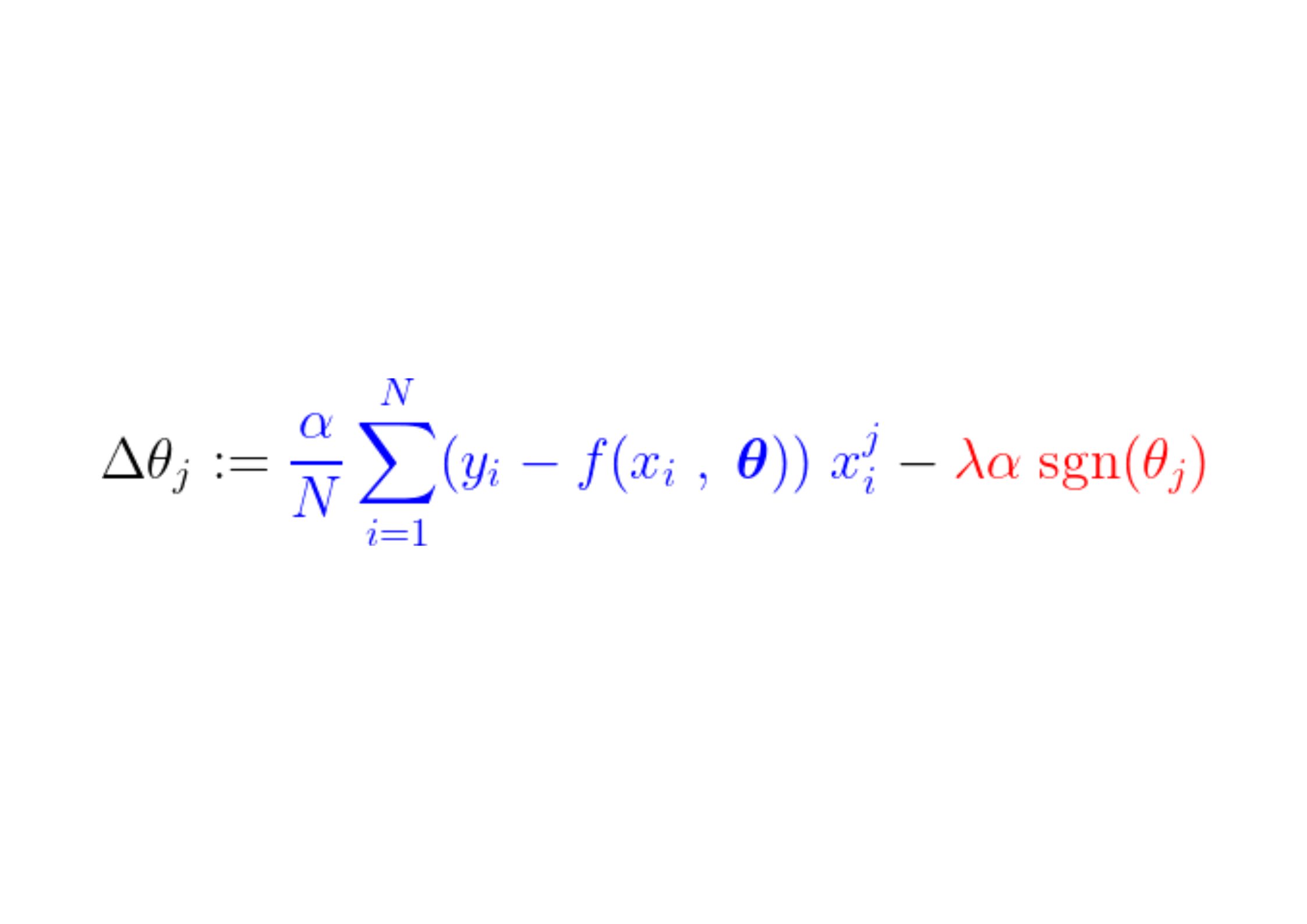
Usted Métodos integrados Seleccionando características de forma implícita, sin utilizar ningún criterio de selección predefinido, y extrayéndolas de los propios datos de entrenamiento. Este proceso de identificación de características esenciales es parte de la fase de entrenamiento del modelo. El modelo aprende a identificar características y hacer predicciones relevantes al mismo tiempo. En las secciones siguientes, describiremos el papel de la regularización en este proceso esencial de selección de características, centrándonos en la regularización L1 y su papel en la mejora de los modelos de aprendizaje automático.
Normalización y complejidad del modelo: estrategias avanzadas para mejorar el rendimiento
La regularización es el proceso de penalizar la complejidad del modelo para evitar el sobreajuste y lograr la generalización a la tarea.
Aquí, la complejidad del modelo es análoga a su capacidad para adaptarse a los patrones en los datos de entrenamiento. Suponiendo un modelo polinomial simple en 'x'hasta cierto punto'd'Cuanto mayor sea la puntuación'dPara los polinomios, el modelo tiene mayor flexibilidad para capturar patrones en los datos observados. Esta mayor flexibilidad puede llevar al modelo a memorizar los datos de entrenamiento en lugar de aprender los patrones verdaderos, lo que reduce su capacidad de generalizar a nuevos datos.
Sobreajuste y subajuste
Al intentar ajustar un modelo polinomial con grado d = 2 En un conjunto de muestras de entrenamiento extraídas de un polinomio de tercer orden con algo de ruido, el modelo no podrá capturar adecuadamente la distribución de muestreo. El modelo simplemente carece Flexibilidad O complejidad Requerido para modelar datos generados por polinomios de grado 3 (o superior). Se dice que este modelo es desadaptado Sobre datos de entrenamiento. La subcarga indica que el modelo es demasiado simple y no puede capturar los patrones subyacentes en los datos.
Trabajando con el mismo ejemplo, ahora asumimos que tenemos un modelo con un grado de d = 6. Ahora, con una mayor complejidad, debería ser fácil para el modelo estimar el polinomio cúbico original que se utilizó para generar los datos (por ejemplo, establecer los coeficientes de todos los términos con exponente > 3 en 0). Si el proceso de entrenamiento no se completa a tiempo, el modelo continuará usando su flexibilidad adicional para reducir aún más el error y comenzará a capturar muestras ruidosas también. Esto reducirá en gran medida el error de entrenamiento, pero el modelo ahora es sobreajustes Sobre datos de entrenamiento. El ruido cambiará en entornos del mundo real (o en la fase de prueba) y cualquier conocimiento basado en predicciones se verá alterado, lo que dará como resultado un alto error de prueba. La sobrecarga significa que el modelo es demasiado complejo y aprende ruido en lugar de la señal real.
¿Cómo determinar la complejidad óptima del modelo?
En entornos prácticos, a menudo tenemos una comprensión limitada o nula del proceso de generación de datos o de la verdadera distribución de los mismos. Encontrar el modelo óptimo con la complejidad apropiada, de modo que no haya sobreajuste ni subajuste, es un desafío importante. Esto requiere el uso de métodos efectivos para evaluar el desempeño de los modelos y determinar la complejidad apropiada que logre el mejor equilibrio entre precisión y generalidad. Al utilizar métricas y técnicas de evaluación adecuadas, como la validación cruzada, los profesionales pueden identificar el modelo que funciona mejor con datos no vistos, evitando así problemas de sobreajuste o subajuste.
Una técnica posible es comenzar con un modelo suficientemente robusto y luego reducir su complejidad mediante la selección de características. Cuanto menos características tenga, menos complejo será el modelo.
Como discutimos en la sección anterior, la selección de características puede ser explícita (métodos de filtrado, métodos de convolución) o implícita. Las características redundantes que no son muy importantes para determinar el valor de la variable objetivo deben eliminarse para evitar que el modelo aprenda patrones no correlacionados en ellas. La regularización también realiza una tarea similar. Entonces, ¿cómo se relacionan la regularización y la selección de características con el logro de un objetivo común de complejidad óptima del modelo? Reducir la complejidad en los modelos de aprendizaje automático es crucial para mejorar el rendimiento y evitar el sobreajuste, que es en lo que se centran tanto la regularización como la selección de características.
La regularización L1 como determinante de características
Continuando con nuestro modelo polinomial, lo representamos como una función f, con entradas x, y transacciones θ y grado d،
![]()
Para un modelo polinomial, cada potencia de la entrada se puede considerar x_i Como ventaja, formar un vector de la siguiente forma:
![]()
También definimos una función objetivo, cuya minimización conduce a los parámetros óptimos. θ * El término incluye: regularización (Reglamento) que penaliza la complejidad del modelo.
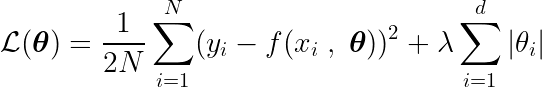
Para encontrar el mínimo de esta función, necesitamos analizar todos los puntos críticos, es decir, los puntos donde la derivada es cero o no está definida.
La derivada parcial se puede escribir con respecto a uno de los parámetros, θj, Como sigue:
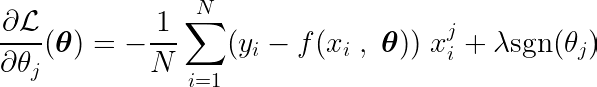
donde se define la función firmar Como sigue:
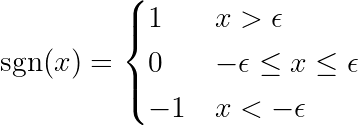
ملاحظةLa derivada de una función absoluta es diferente de la función signo (sgn) definida anteriormente. La derivada original no está definida en x = 0. Extendemos la definición para eliminar el punto de inflexión en x = 0 y hacer que la función sea diferenciable en todo su rango. Además, los marcos de aprendizaje automático (ML) utilizan estas funciones extendidas cuando los cálculos subyacentes involucran la función absoluta. ¡Mira esto! Enlace En el foro de PyTorch.
Calculando la derivada parcial de la función objetivo con respecto a un único coeficiente θj, y al igualarlo a cero, podemos construir una ecuación que vincule el valor óptimo de θj Con predicciones, objetivos y características.
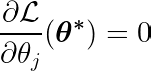
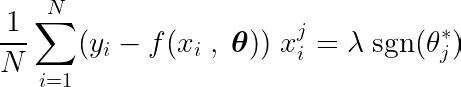
Examinemos la ecuación anterior. Suponiendo que las entradas y los objetivos se centraron alrededor de la media (es decir, los datos se estandarizaron en el paso de preprocesamiento), el término en el lado izquierdo (LHS) representa efectivamente diferencia Entre el número de característica j y la diferencia entre los valores esperados y objetivo.
La covarianza estadística entre dos variables determina la cantidad de influencia que una variable tiene sobre el valor de la segunda variable (y viceversa).
La función de signo en el lado derecho fuerza la variación en el lado izquierdo a asumir solo tres valores (ya que la función de signo solo devuelve -1, 0 y 1). Si la función j Innecesario y no afecta las predicciones, la varianza será cercana a cero, lo que hace que el coeficiente correspondiente θj* Cero. Esto provoca que la característica se elimine del modelo. Este proceso ayuda a reducir la complejidad y mejorar el rendimiento del modelo.
Imagine la función del cartel como un surco tallado por el agua. Se puede caminar dentro del barranco (es decir, el lecho del río), pero para salir de él, se encontrará con enormes barreras o rápidos pronunciados. La regularización L1 crea un efecto de “umbral” similar al gradiente de la función de pérdida. El gradiente debe ser lo suficientemente fuerte como para romper las barreras o convertirse en cero, haciendo eventualmente que el valor del coeficiente sea cero.
Para proporcionar un ejemplo más realista, considere un conjunto de datos que contiene muestras derivadas de una línea recta (parametrizada con dos factores) con algo de ruido agregado. El modelo óptimo no debe tener más de dos parámetros; de lo contrario, se ajustará al ruido de los datos (con la libertad/potencia adicionales del polinomio). Cambiar los coeficientes de potencia más altos en un modelo polinomial no afecta la diferencia entre los objetivos y las predicciones del modelo y, por lo tanto, reduce su variación con la característica.
Durante el proceso de entrenamiento, se agrega/resta un paso fijo al gradiente de la función de pérdida. Si el gradiente de la función de pérdida (MSE – error cuadrático medio) es menor que el paso constante, el coeficiente eventualmente alcanzará un valor de 0. Observe la ecuación a continuación, que muestra cómo se actualizan los coeficientes mediante el descenso de gradiente:

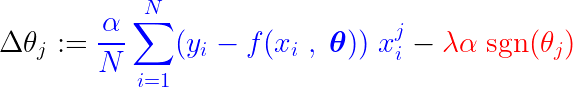
Si la parte azul de arriba es más pequeña que La, que es un número muy pequeño en sí mismo, entonces Δθj Es casi un paso constante. La. La señal para este paso (parte roja) depende de: signo(θj), cuya producción depende de θj. Si el valor es θj Positivo, es decir mayor que ε, los signo(θj) es igual a 1, por lo que hace Δθj Aproximadamente igual a -La, empujándolo hacia cero.
Para suprimir el paso constante (parte roja) que hace que el coeficiente sea cero, el gradiente de la función de pérdida (parte azul) debe ser mayor que el tamaño del paso. Para obtener un gradiente mayor para la función de pérdida, el valor de la característica debe afectar significativamente la salida del modelo.
Así es como la característica, o más precisamente, su parámetro correspondiente, cuyo valor no está relacionado con la salida del modelo, se pone a cero mediante la regularización L1 durante el entrenamiento.
Lecturas adicionales y conclusión
- Para obtener más información sobre este tema, publiqué una pregunta en Reddit r/MachineLearning yHacer un seguimiento Contiene diferentes interpretaciones que quizá quieras leer.
- Madiyar Aitbayev también tiene blog interesante Cubre la misma pregunta, pero con una explicación de ingeniería.
- مدونة Brian King explica la organización desde una perspectiva probabilística.
- هذا النقاش En el sitio web CrossValidated explica por qué el criterio L1 fomenta los modelos dispersos. مدونة Un artículo detallado de Mukul Ranjan explica por qué la norma L1 fomenta que las transacciones sean cero y la norma L2 no.
“La regularización L1 selecciona características” es una afirmación simple con la que la mayoría de los estudiantes de ML están de acuerdo, sin entrar en detalles sobre cómo funciona internamente. Este blog es un intento de presentar mi comprensión y modelo mental a los lectores para poder responder la pregunta de una manera intuitiva. Para sugerencias y dudas, puedes encontrar mi correo en Mi sitio web. ¡Sigue aprendiendo y que tengas un día maravilloso!
Los comentarios están cerrados.