

Meta enseña a los modelos de IA el arte de distinguir entre comandos importantes y otros.
Los modelos de razonamiento como OpenAI o1 y DeepSeek-R1 tienen un problema con el pensamiento excesivo. Si le haces una pregunta sencilla como “¿Cuánto es 1 + 1?”, pensará durante varios segundos antes de responder.

Lo ideal sería que los modelos de IA, al igual que los humanos, pudieran determinar cuándo dar una respuesta directa y cuándo asignar tiempo y recursos adicionales para pensar antes de responder. Y lo hace nueva tecnología Presentado por investigadores en Meta IA وUniversidad de Illinois en Chicago Entrenando modelos para asignar presupuestos de inferencia en función de la dificultad de la consulta. Esto da como resultado respuestas más rápidas, menores costos y una mejor asignación de recursos informáticos.
razonamiento costoso
Los modelos de lenguaje grandes (LLM) pueden mejorar su desempeño en tareas de razonamiento cuando producen cadenas de pensamiento más largas, a menudo conocidas como “cadenas de pensamiento” (CoT). El éxito de la técnica de la cadena de ideas ha dado lugar a todo un conjunto de técnicas de escalamiento del tiempo de inferencia que obligan al modelo a “pensar” más profundamente sobre el problema, generar y revisar múltiples respuestas y elegir la mejor.
La votación mayoritaria (MV) es uno de los principales métodos utilizados en los modelos de razonamiento, donde se generan múltiples respuestas y se elige la respuesta más frecuentemente preguntada. El problema con este enfoque es que el modelo adopta un comportamiento uniforme, tratando cada entrada como un problema de razonamiento difícil y consumiendo recursos innecesarios para generar múltiples respuestas.
Razonamiento inteligente
El nuevo artículo de investigación propone una serie de técnicas de entrenamiento que hacen que los modelos de razonamiento sean más eficientes al responder. El primer paso es la “votación secuencial” (VS), donde el modelo interrumpe el proceso de razonamiento una vez que una respuesta particular ha aparecido una cierta cantidad de veces. Por ejemplo, se pide al formulario generar un máximo de ocho respuestas y elegir la respuesta que aparece al menos tres veces. Si se le da al modelo la consulta simple anterior, es probable que las primeras tres respuestas sean similares, lo que dará lugar a una detención temprana, ahorrando tiempo y recursos computacionales.
Sus experimentos muestran que SV supera a MV clásico en problemas de competencia matemática cuando genera la misma cantidad de respuestas. Sin embargo, SV requiere instrucciones adicionales y generación de código, lo que lo pone a la par de MV en términos de relación código-precisión.
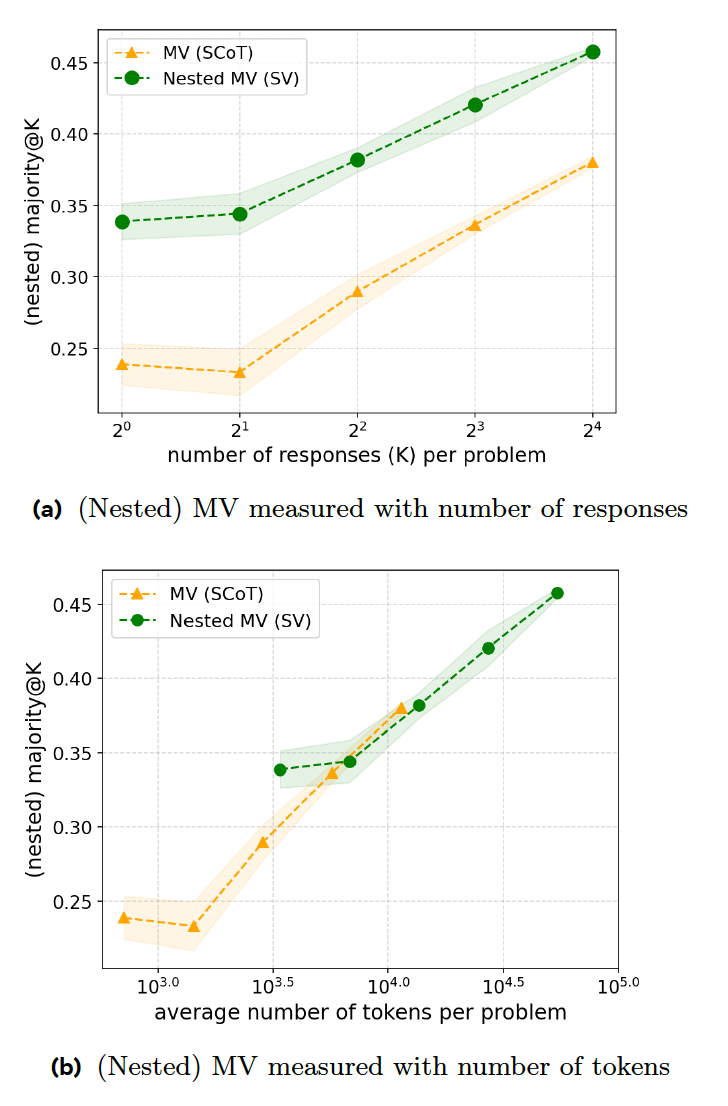
La segunda técnica, votación secuencial adaptativa (ASV), mejora la SV al requerir que el modelo examine el problema y genere múltiples respuestas solo cuando el problema es difícil. Para problemas simples (como una afirmación 1+1), el modelo simplemente genera una única respuesta sin pasar por el proceso de votación. Esto hace que el modelo sea más eficiente al manejar problemas tanto simples como complejos.
Aprendizaje reforzado
Si bien las técnicas SV y ASV mejoran la eficiencia del modelo, requieren una gran cantidad de datos etiquetados manualmente. Para mitigar este problema, los investigadores proponen “optimización de políticas con presupuesto de inferencia restringido” (IBPO), un algoritmo de aprendizaje de refuerzo que enseña al modelo a ajustar la longitud de las rutas de razonamiento en función de la dificultad de la consulta.
IBPO está diseñado para permitir que los modelos de lenguaje grandes (LLM) mejoren sus respuestas mientras se mantienen dentro de las limitaciones del presupuesto de inferencia. El algoritmo de aprendizaje de refuerzo permite que el modelo supere las ganancias obtenidas mediante el entrenamiento con datos etiquetados manualmente al generar continuamente trayectorias ASV, evaluar respuestas y seleccionar resultados que brinden la respuesta correcta y el presupuesto de inferencia óptimo.
Sus experimentos muestran que IBPO mejora el frente de Pareto, lo que significa que, para un presupuesto de inferencia fijo, un modelo entrenado en IBPO supera a otras líneas de base.
Estos hallazgos llegan en medio de advertencias de los investigadores de que los modelos actuales de IA están teniendo dificultades. Mientras las empresas luchan por encontrar datos de capacitación de alta calidad y exploran formas alternativas de mejorar sus modelos.
Una solución prometedora es el aprendizaje de refuerzo, donde se le da un objetivo al modelo y se le permite encontrar sus propias soluciones, a diferencia del ajuste fino supervisado (SFT), donde el modelo se entrena con ejemplos etiquetados manualmente.
Sorprendentemente, el modelo a menudo encuentra soluciones que los humanos no habían pensado. Esta es una fórmula que parece haber funcionado con DeepSeek-R1, que desafió el dominio de los laboratorios de IA estadounidenses.
Los investigadores señalan que «los métodos basados en indicaciones y la SFT tienen dificultades para lograr una optimización y eficiencia absolutas, lo que respalda la conjetura de que la SFT por sí sola no permite la autocorrección. Esta observación también se ve respaldada por trabajos concurrentes, que sugieren que este comportamiento autocorrectivo surge espontáneamente durante el aprendizaje por refuerzo, en lugar de generarse manualmente mediante indicaciones o la SFT».
Los comentarios están cerrados.