

Mejora de la detección en modelos de Transformers añadiendo ruido de entrenamiento
Los modelos de visión de Transformer modernos agregan ruido para mejorar el rendimiento de detección de objetos 2D y 3D. En este artículo, aprenderemos cómo funciona este mecanismo y discutiremos su contribución a la mejora de la precisión de los modelos de detección de objetos, centrándonos en el uso de técnicas como la eliminación de ruido en el proceso de entrenamiento.

Modelos transformadores para la visión temprana
DETR – DEtection TRansformer (Carion, Massa et al. 2020), una de las primeras arquitecturas de Transformer para la detección de objetos, utilizó consultas de codificador-decodificador aprendidas para extraer información de detección de tokens de imagen. Estas consultas se inicializaron de forma aleatoria y la arquitectura no impuso ninguna restricción que obligara a estas consultas a aprender objetos similares a anclas. Si bien logró resultados similares con Faster-RCNN, su desventaja fue su convergencia lenta: se necesitaron 500 épocas para entrenarlo (DN-DETR, Li et al., 2024). Las arquitecturas más recientes basadas en DETR utilizaron agrupamiento deformable que permitió que las consultas se centraran solo en regiones específicas de la imagen (Zhu et al., Deformable DETR: Deformable Transformers For End-To-End Object Detection, 2020), mientras que otras (Liu et al., DAB-DETR: Dynamic Anchor Boxes Are Better Queries For DETR, 2022) utilizaron anclajes espaciales (generados utilizando k-means, de manera similar a como lo hacen las CNN basadas en anclajes), que se codificaron en las consultas iniciales. Las conexiones de salto obligan al bloque decodificador del Transformador a aprender los cuadrados como valores de pendiente de los anclajes. Las capas de atención deformables utilizan anclajes precodificados para tomar muestras de características espaciales de la imagen y usarlas para generar tokens de atención. Durante el entrenamiento, el modelo aprende los anclajes ideales a utilizar. Este enfoque enseña al modelo a utilizar características como el tamaño del cuadro explícitamente en sus consultas.
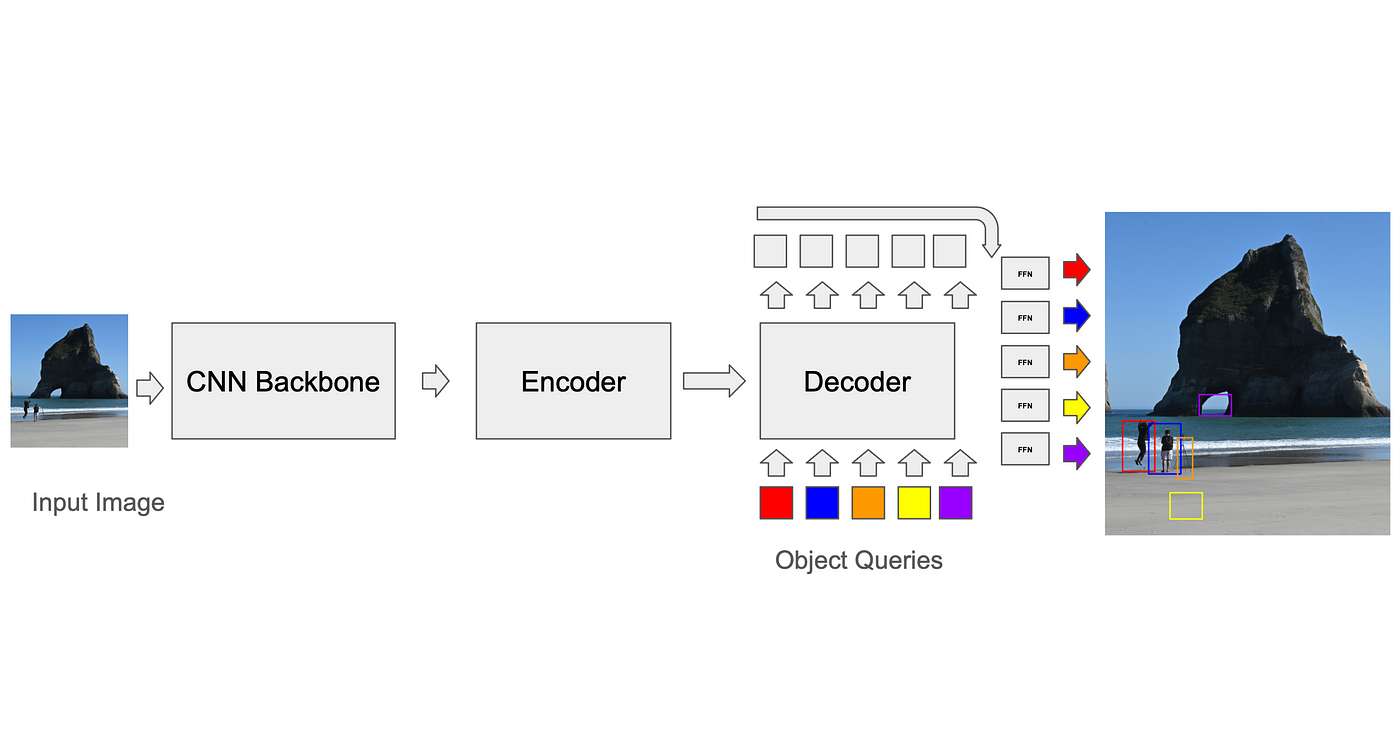
Coincidencia de predicciones con datos fundamentales: algoritmo de coincidencia binaria
Para calcular la pérdida, el entrenador primero debe hacer coincidir las predicciones del modelo con los cuadros de verdad fundamental (GT). Si bien las CNN basadas en anclajes tienen soluciones relativamente fáciles para este problema (por ejemplo, cada anclaje solo se puede asociar con cuadros GT en su vóxel durante el entrenamiento y, en la inferencia, se utiliza una supresión no máxima para eliminar las detecciones superpuestas), el estándar para transformadores, desarrollado por DETR, es utilizar un algoritmo de coincidencia binaria llamado algoritmo húngaro. En cada iteración, el algoritmo encuentra la mejor coincidencia entre la predicción y la verdad fundamental (una coincidencia que optimiza una función de costo, como la distancia cuadrática media entre las esquinas de las cajas, sumada a todas las cajas). Luego se calcula la pérdida entre los pares predictor-verdad fundamental y se puede retropropagar. Las predicciones excesivas (predicciones sin coincidencia GT) generan una pérdida discreta que las incentiva a reducir su puntuación de confianza. Este proceso es necesario para mejorar la precisión del modelo y reducir los errores.
el problema
La complejidad temporal del algoritmo húngaro es o(n³). Curiosamente, esto no es necesariamente un cuello de botella en la calidad del entrenamiento: The Stable Marriage Problem: An Interdisciplinary Review From The Physicist's Perspective, Fenoaltea et al., 2021, muestra que el algoritmo es inestable, lo que significa que un pequeño cambio en su función objetivo puede conducir a un gran cambio en su resultado de coincidencia, lo que genera objetivos de entrenamiento de consultas inconsistentes. Las implicaciones prácticas del entrenamiento del transformador son que las consultas de objetos pueden saltar entre objetos y lleva mucho tiempo aprender las mejores características para la convergencia. En otras palabras, la inestabilidad del algoritmo conduce a oscilaciones en el proceso de entrenamiento, lo que requiere mayor tiempo para alcanzar los mejores resultados.
DN-DETR (Detección de objetos por eliminación de ruido)
Li y otros. propuso una solución elegante al problema de emparejamiento inestable, que luego fue adoptada en muchos otros trabajos, incluidos DINO, Mask DINO, Group DETR y otros.
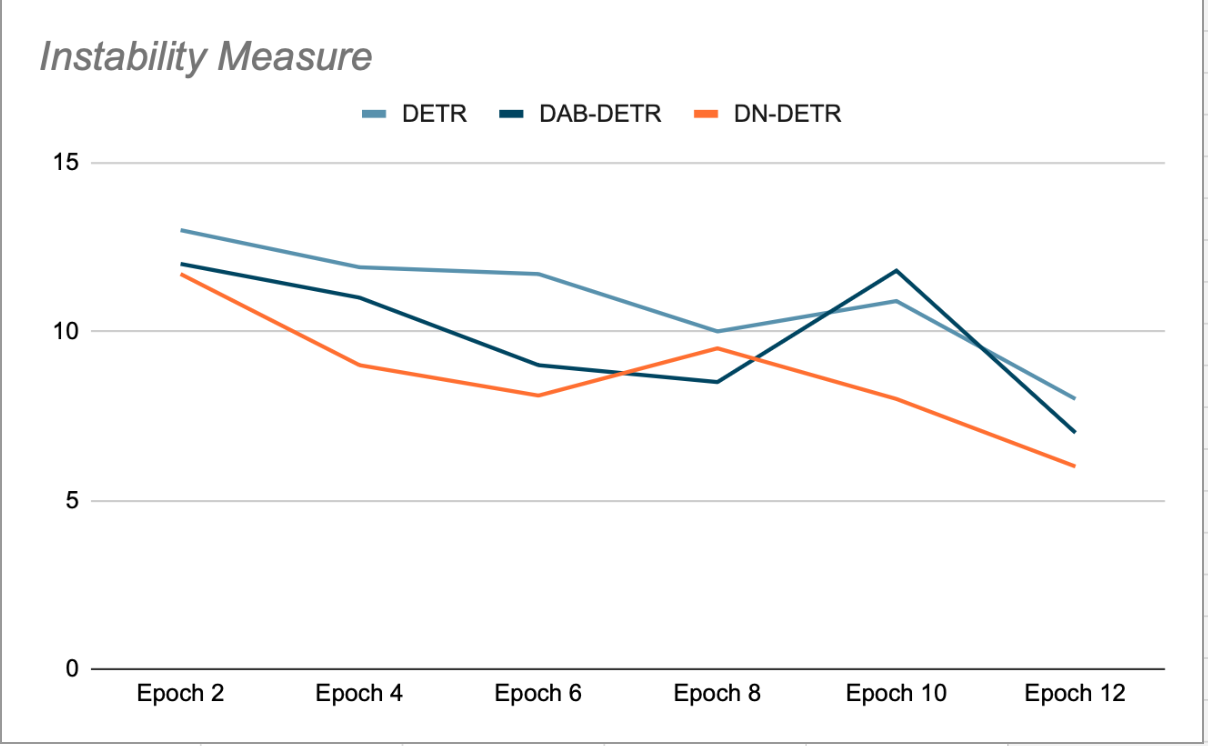
La idea principal de DN-DETR es mejorar la formación mediante la creación de Puntos de pivote imaginarios fáciles de inclinarSe omite el proceso de emparejamiento. Esto se realiza durante el entrenamiento añadiendo una pequeña cantidad de ruido a las teselas GT (base real) y alimentando estas teselas ruidosas como anclas para las consultas del decodificador. Las consultas DN se enmascaran de las consultas orgánicas y viceversa, para evitar la atención cruzada que podría interferir con el entrenamiento. Las detecciones generadas por estas consultas ya están emparejadas con sus teselas GT de origen y no requieren emparejamiento bipartito. Los autores de DN-DETR demostraron que, durante las fases de validación al final de cada época (donde la eliminación de ruido está desactivada), esto mejora la estabilidad del modelo en comparación con DETR y DAB-DETR, lo que significa que las consultas Plus son consistentes en su emparejamiento con el objeto GT en épocas sucesivas (véase la Figura 2).
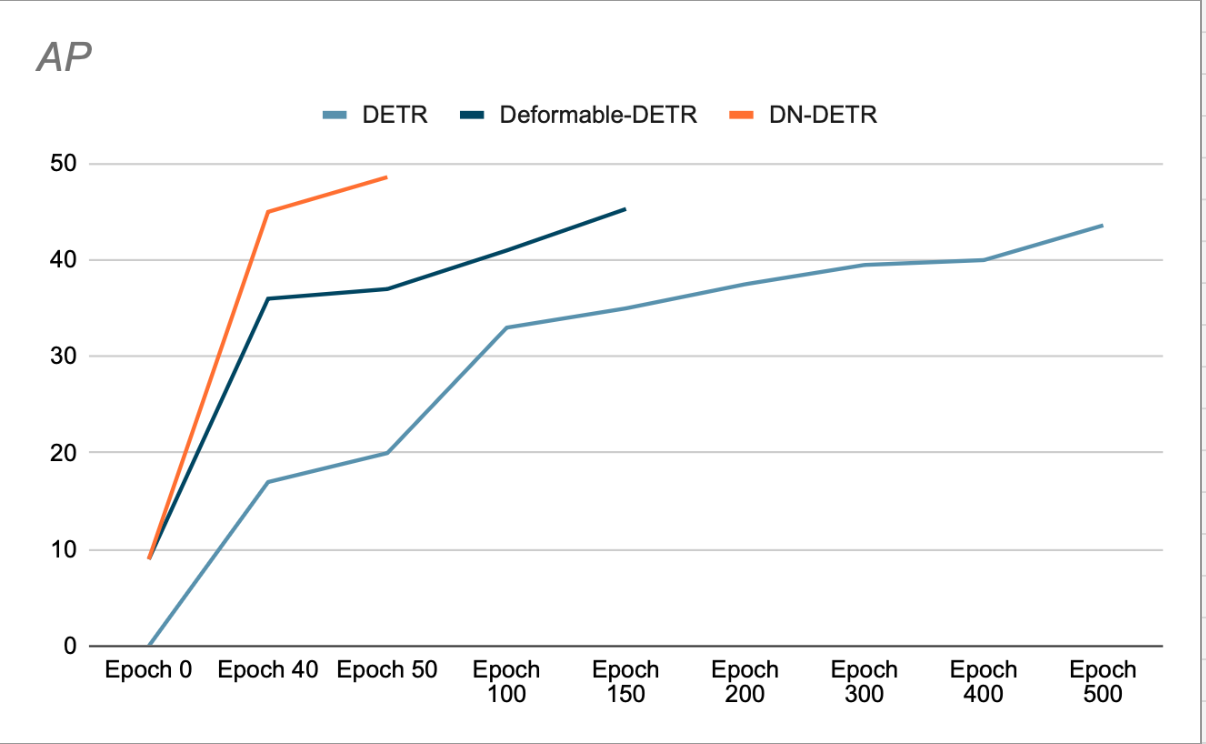
Los autores demuestran que el uso de DN acelera la convergencia y logra mejores resultados de detección. (Ver Figura 3). Su estudio de eliminación muestra un aumento del 1.9% en AP (precisión promedio) en el conjunto de datos de detección COCO, en comparación con el SOTA anterior (DAB-DETR, AP 42.2%), cuando se utiliza ResNet-50 como red troncal.
Eliminación de ruido de contraste y DINO
DINO desarrolló esta idea aún más, agregando aprendizaje contrastivo al mecanismo de eliminación de ruido: además del ejemplo positivo, DINO crea otra versión con ruido de cada GT, que se construye matemáticamente para estar más alejada del GT que el ejemplo positivo (ver Figura 4). Esta versión se utiliza como un ejemplo negativo para el entrenamiento: el modelo aprende a aceptar la detección más cercana a la verdad fundamental y a rechazar la detección más lejana (aprendiendo a predecir la clase “ningún objeto”).
Además, DINO permite la agrupación múltiple para la eliminación de ruido contrastivo (CDN), es decir, múltiples anclajes ruidosos para cada objeto GT, lo que permite aprovechar al máximo cada iteración de entrenamiento.
Los autores de DINO informaron una precisión promedio (AP) del 49% (en COCO val2017) al usar una CDN.
Los modelos temporales modernos que necesitan rastrear objetos de un cuadro a otro, como Sparse4Dv3, usan CDN y agregan grupos de eliminación de ruido temporal, donde se almacenan algunos anclajes DN exitosos (junto con los anclajes no DN aprendidos) para usar en cuadros posteriores, lo que mejora el rendimiento del modelo en el seguimiento de objetos.

مناقشة
La eliminación de ruido (DN) parece mejorar la velocidad de convergencia y el rendimiento final de los detectores de transformadores de visión. Sin embargo, al examinar el desarrollo de los diversos métodos mencionados anteriormente, surgen las siguientes preguntas:
- DN mejora los modelos que utilizan anclajes que se pueden aprender. Pero ¿son realmente importantes los anclajes que se pueden aprender? ¿DN también mejorará los modelos que utilizan anclajes que no se pueden aprender?
- La principal contribución de DN al entrenamiento es agregar estabilidad al proceso de descenso de gradiente evitando la correspondencia bipartita. Pero la correspondencia binaria parece existir principalmente porque la norma en el trabajo con transformadores es evitar restricciones espaciales en las consultas. Entonces, si restringimos manualmente las consultas a ubicaciones de imágenes específicas y abandonamos la coincidencia binaria (o usamos una versión simplificada de coincidencia binaria, que se ejecuta en cada parche de imagen por separado), ¿DN seguirá mejorando los resultados?
No pude encontrar obras que proporcionaran respuestas claras a estas preguntas. Mi hipótesis es que un modelo que utiliza anclas que no se pueden aprender (siempre que las anclas no sean demasiado dispersas) y consultas restringidas espacialmente, 1 – no requerirá un algoritmo de coincidencia binaria, y 2 – no se beneficiará de DN en el entrenamiento, ya que las anclas ya son conocidas y no hay ganancia en aprender regresión a partir de otras anclas efímeras.
Si los anclajes son fijos pero dispersos, puedo ver cómo el uso de anclajes efímeros hace más fácil el descenso y puede proporcionar un comienzo cálido al proceso de entrenamiento.
Anchor-DETR (Wand et al., 2021) compara la distribución espacial de los anclajes aprendibles y no aprendibles, y el rendimiento de los respectivos modelos y, en mi opinión, la capacidad de aprendizaje no agrega mucho valor al rendimiento del modelo. Vale la pena señalar que utilizan el algoritmo húngaro en ambos métodos, por lo que no está claro si podrían abandonar la coincidencia binaria y aún así mantener el rendimiento.
Una consideración a tener en cuenta es que puede haber razones productivas para evitar NMS en la inferencia, lo que fomenta el uso del algoritmo húngaro en el entrenamiento.
¿Dónde puede realmente importar la eliminación del ruido? En mi opinión - en Trazabilidad. Durante el seguimiento, el modelo cuenta con una transmisión de video y es necesario no solo para detectar múltiples objetos en cuadros consecutivos, sino también para mantener la identidad única de cada objeto detectado. Los modelos de transformadores temporales, es decir, modelos que utilizan la naturaleza secuencial de la transmisión de video, no procesan cuadros individuales de forma independiente. En lugar de ello, mantiene un banco que almacena descubrimientos anteriores. Durante el entrenamiento, se anima al modelo de seguimiento a retroceder desde la detección del objeto anterior (o más precisamente, el fijador asociado con la detección del objeto anterior), en lugar de simplemente retroceder desde el fijador más cercano. Dado que el descubrimiento anterior no está restringido a alguna red fija de estabilizadores, es plausible que la flexibilidad estimulada por DN sea beneficiosa. Me gustaría mucho leer futuros trabajos que aborden estos temas.
¡Eso es todo sobre la eliminación de ruido y su contribución a los transformadores de visión! Si te gustó mi artículo, estás invitado a visitar algunos de mis otros artículos sobre aprendizaje profundo y aprendizaje automático y visión artificial!
Los comentarios están cerrados.