

Evaluación del rendimiento de los modelos destilados de DeepSeek-R1 en GPQA utilizando Ollama y evaluaciones simples de OpenAI
Configure y ejecute el punto de referencia GPQA-Diamond en modelos DeepSeek-R1 destilados localmente para evaluar sus capacidades de inferencia.
Lanzamiento del último modelo DeepSeek-R1 Ampliamente resonado en la comunidad global de IA. Ha logrado avances comparables a los modelos de inferencia de Meta y OpenAI, y lo ha hecho en una fracción del tiempo y a un costo mucho menor.
Pero más allá de los titulares y la publicidad online, ¿cómo podemos evaluar las capacidades de inferencia de un modelo utilizando criterios reconocidos? Ésta es una pregunta importante para los expertos en IA.
. Interfaz de usuario Búsqueda profunda Facilita la exploración de sus capacidades, pero su uso programático proporciona conocimientos más profundos y una integración más fluida en aplicaciones del mundo real. Comprender cómo funcionan estos modelos a nivel local también proporciona un mejor control y acceso fuera de línea.

En este artículo, exploraremos cómo utilizar Ollamayevaluaciones simples de OpenAI Evaluar las capacidades de inferencia de los modelos destilados de DeepSeek-R1 basados en el punto de referencia GPQA-Diamante Famoso. Este criterio se considera una de las herramientas más importantes para evaluar modelos de inteligencia artificial en el campo del razonamiento lógico.
aquí Enlace al repositorio de GitHub Acompañando este artículo.
(1) ¿Cuáles son los modelos de razonamiento?
Los modelos de inferencia, como DeepSeek-R1 y los modelos de la serie o de OpenAI (por ejemplo, o1, o3), son modelos de lenguaje grandes (LLM) entrenados mediante aprendizaje de refuerzo para realizar inferencias. Estos modelos son herramientas avanzadas en el campo de la inteligencia artificial y representan el pináculo de la evolución en la capacidad de las máquinas para pensar lógicamente y resolver problemas complejos.
Las heurísticas se caracterizan por una reflexión profunda antes de responder, produciendo una larga serie de pensamientos internos antes de responder. Se destaca en la resolución de problemas complejos, programación, razonamiento científico y planificación de múltiples pasos de flujos de trabajo de agentes. Estas capacidades los hacen indispensables en campos como el desarrollo de software avanzado, la investigación científica y la automatización de procesos complejos.
(2) ¿Qué es el modelo DeepSeek-R1?
DeepSeek-R1 es un modelo de lenguaje grande (LLM) de código abierto de última generación, diseñado específicamente para Razonamiento avanzado. Enviado en enero de 2025 en el artículo de investigación "DeepSeek-R1: Aumento del poder de inferencia en modelos lingüísticos extensos mediante aprendizaje por refuerzo". DeepSeek-R1 es un modelo pionero en el campo de la inteligencia artificial.
Este modelo se basa en una arquitectura de modelo de lenguaje grande (LLM) con 671 mil millones de parámetros y se entrenó utilizando un aprendizaje de refuerzo (RL) extenso basado en la siguiente ruta:
- Las dos etapas del aumento tienen como objetivo descubrir patrones de razonamiento mejorados y alinearse con las preferencias humanas.
- Dos etapas de ajuste fino supervisado sirven como semilla para las capacidades de inferencia y no inferencia del modelo.
Para ilustrarlo, DeepSeek entrenó dos modelos:
- El primer modelo, DeepSeek-R1-Cero, es un modelo de inferencia entrenado mediante aprendizaje de refuerzo y genera datos para entrenar el segundo modelo, DeepSeek-R1.
- Esto se logra mediante la producción de rastros de inferencia, de los cuales solo se conservan los de alta calidad en función de sus resultados finales.
- Esto significa que, a diferencia de la mayoría de los modelos, los ejemplos de aprendizaje de refuerzo (RL) en este proceso de entrenamiento no son seleccionados por humanos, sino que son generados por el modelo mismo.
El resultado es que el modelo logró un rendimiento similar al de los modelos líderes como Modelo o1 de OpenAI En tareas como matemáticas, programación y razonamiento complejo.
(3) Comprensión del proceso de destilación y los modelos destilados de DeepSeek-R1
Además del modelo completo, también abrieron el código fuente de seis modelos densos más pequeños (también llamados DeepSeek-R1) de diferentes tamaños (1.5B, 7B, 8B, 14B, 32B, 70B), destilados a partir de DeepSeek-R1 en base a Qwen O Llama Como modelo básico.
Destilación Es una técnica en la que se entrena a un modelo más pequeño (“estudiante”) para replicar el desempeño de un modelo más grande y poderoso que ha sido entrenado previamente (“profesor”).
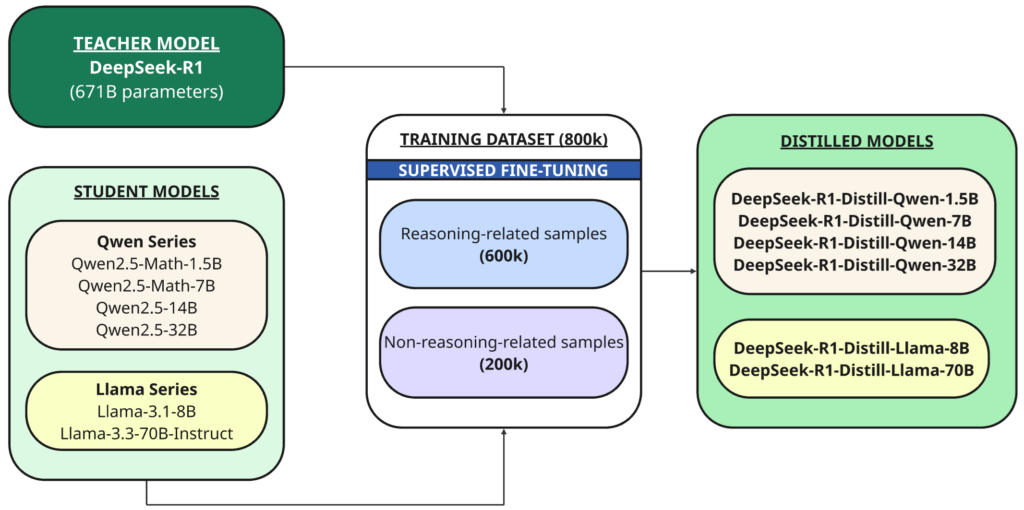
En este caso, el profesor es el modelo 1B DeepSeek-R671 y los estudiantes son los seis modelos destilados utilizando este modelo base de código abierto:
- Qwen2.5 — Matemáticas-1.5B
- Qwen2.5 — Matemáticas-7B
- Qwen2.5 — 14B
- Qwen2.5 — 32B
- Llama-3.1 — 8B
- Llama-3.3 — 70B-Instrucciones
DeepSeek-R1 se utilizó como modelo docente para generar 800,000 muestras de entrenamiento, una mezcla de muestras de inferencia y no inferencia, para su destilación a través de ajuste fino supervisado Para modelos básicos (1.5B, 7B, 8B, 14B, 32B y 70B).
Entonces, ¿por qué destilamos en primer lugar?
El objetivo es transferir las capacidades de inferencia de modelos más grandes, como DeepSeek-R1 671B, a modelos más pequeños y más eficientes. Esto permite que modelos más pequeños manejen tareas de inferencia complejas y al mismo tiempo sean más rápidos y más eficientes en el uso de recursos.
Además, DeepSeek-R1 tiene una cantidad enorme de parámetros (671 mil millones), lo que dificulta su ejecución en la mayoría de los dispositivos de consumo.
Incluso el MacBook Pro más potente, con una memoria unificada máxima de 128 GB, no es suficiente para ejecutar un modelo con parámetros de 671 mil millones.
Como tal, los modelos destilados abren la posibilidad de implementarlos en dispositivos con recursos computacionales limitados.
logrado perezoso Un logro notable al cuantificar el modelo original DeepSeek-R1 de 671 mil millones de parámetros a solo 131 GB: una notable reducción del 80 % en el tamaño. Sin embargo, el requisito de 131 GB de VRAM sigue siendo un obstáculo importante, especialmente para los desarrolladores que trabajan en dispositivos con recursos limitados. Este logro representa un paso significativo para hacer que los modelos de IA de gran tamaño sean accesibles para una gama más amplia de usuarios.
(4) Selección del modelo destilado óptimo
Con seis tamaños diferentes de modelos destilados para elegir, determinar el modelo correcto depende en gran medida de las capacidades de su equipo local.
Para aquellos con GPU o CPU de alto rendimiento que necesitan el máximo rendimiento, los modelos DeepSeek-R1 más grandes (32B y superiores) son ideales; incluso la versión cuántica 671B es viable.
Sin embargo, si los recursos son limitados o prefieres tiempos de construcción más rápidos (como yo), las variantes destiladas más pequeñas, como 8B o 14B, son una mejor opción. Esto equilibra el rendimiento y los requisitos de recursos.
Para este proyecto, utilizaré el modelo destilado DeepSeek-R1. Qwen-14B, que corresponde a las limitaciones de hardware que encontró. Este modelo (14B) representa un excelente compromiso entre precisión y velocidad, lo que lo hace perfecto para mi entorno de desarrollo.
(5) Criterios para evaluar la capacidad de inferencia de modelos lingüísticos grandes
Los modelos de lenguaje grandes (LLM) generalmente se evalúan utilizando métricas estandarizadas que determinan su desempeño en diversas tareas, incluida la comprensión del lenguaje, la generación de código, el seguimiento de instrucciones y la respuesta de preguntas. Algunos ejemplos comunes incluyen métricas como: MMLU,yevaluación humana,yMGSM. Estas métricas son esenciales para evaluar las capacidades de los modelos lingüísticos grandes.
Para medir la capacidad de razonamiento de un modelo lingüístico grande, necesitamos parámetros de referencia más desafiantes que se centren en gran medida en el razonamiento y vayan más allá de las tareas superficiales. A continuación se presentan algunos ejemplos comunes que se centran en evaluar capacidades de razonamiento avanzadas:
(i) Examen AIME 2024: Matemáticas Competitivas
- Preparar Examen Americano de Matemáticas por Invitación (AIME) 2024 Un punto de referencia sólido para evaluar las capacidades de los modelos de lenguaje grandes (LLM) en el razonamiento matemático.
- Este examen representa un desafío importante en las matemáticas competitivas, ya que presenta problemas complejos de varios pasos. El examen evalúa la capacidad de los modelos lingüísticos grandes para comprender preguntas complejas, aplicar razonamiento avanzado y realizar manipulaciones simbólicas precisas. El AIME es una medida importante para evaluar habilidades de resolución de problemas matemáticos complejos.
(ii) Codeforces – Código de Competencia
- levantarse Estándar de Codeforces Evaluación de la capacidad de inferencia de un modelo de lenguaje grande (LLM) utilizando problemas de programación competitiva del mundo real de Codeforces, una plataforma conocida por sus desafíos algorítmicos. Codeforces es el estándar de oro para evaluar las capacidades de los modelos de IA para resolver problemas complejos.
- Estos problemas ponen a prueba la capacidad de un modelo de lenguaje grande (LLM) para comprender instrucciones complejas, realizar razonamientos lógicos y matemáticos, planificar soluciones de varios pasos y generar código correcto y eficiente. Estos problemas requieren una comprensión profunda de algoritmos y estructuras de datos, así como la capacidad de traducir el problema en código ejecutable.
(iii) GPQA Diamond: preguntas científicas de nivel de doctorado
- GPQA-Diamond es un subconjunto seleccionado de Las preguntas más difíciles Desde el estándar GPQA (Preguntas y respuestas de Física de Posgrado) El modelo más amplio y específicamente diseñado para ampliar los límites de la capacidad de los modelos LLM para inferir temas avanzados de nivel de doctorado. Esta norma representa un verdadero desafío a la capacidad de la IA para comprender e inferir conceptos científicos complejos.
- Mientras que el GPQA incluye un conjunto de preguntas de posgrado conceptuales y basadas en cálculos, el GPQA-Diamond aísla solo las preguntas más desafiantes y aquellas que requieren un razonamiento intensivo.
- Este criterio se considera “resistente a Google”, lo que significa que es difícil de responder incluso con acceso web sin restricciones. Esto lo convierte en una herramienta valiosa para evaluar la capacidad de los modelos de lenguaje grandes para razonar de forma independiente.
- A continuación se muestra un ejemplo de una pregunta GPQA-Diamond:
### GPQA Diamond - Pregunta de ejemplo (Biología molecular) Una célula eucariota desarrolló un mecanismo para convertir los componentes básicos macromoleculares en energía. El proceso ocurre en las mitocondrias, que son fábricas de energía celular. En la serie de reacciones redox, la energía de los alimentos se almacena entre los grupos fosfato y se utiliza como moneda celular universal. Las moléculas cargadas de energía son transportadas fuera de la mitocondria para servir en todos los procesos celulares. Descubrió un nuevo fármaco contra la diabetes y quiere investigar si tiene efecto sobre las mitocondrias. Configura una serie de experimentos con tu línea celular HEK293. ¿Cuál de los experimentos enumerados a continuación no le ayudará a descubrir el papel mitocondrial de su fármaco? (A) Extracción por centrifugación diferencial de mitocondrias seguida del kit de ensayo colorimétrico de captación de glucosa (B) Citometría de flujo después del marcaje con 2.5 µM de yoduro de 5,5',6,6'-tetracloro-1,1',3,3'-tetraetilbenzimidazolilcarbocianina (C) Transformación de células con luciferasa recombinante y lectura del luminómetro después de añadir 5 µM de luciferina al sobrenadante (D) Microscopía de fluorescencia confocal después de la tinción Mito-RTP de las células
En este proyecto, Utilizamos GPQA-Diamond como estándar para la conclusión., tal como lo usé OpenAIybúsqueda profunda Para evaluar sus modelos de inferencia. La elección de GPQA-Diamond como criterio de evaluación es una evidencia de su dificultad e importancia en el campo del desarrollo de la IA.
(6) Herramientas utilizadas
En este proyecto utilizamos principalmente Ollamayevaluaciones simples De OpenAI. Ollama es una plataforma poderosa para ejecutar modelos de lenguaje grandes localmente, mientras que simple-evals proporciona un marco para evaluar el rendimiento de estos modelos.
(i) Ollama
Ollama Es una herramienta de código abierto que simplifica la ejecución de modelos de lenguaje grandes (LLM) en nuestra computadora o en un servidor local. Olama es una plataforma ideal para ejecutar modelos de IA localmente.
Actúa como administrador y entorno de ejecución, gestionando tareas como descargas y configuración del entorno. Esto permite a los usuarios interactuar con estos modelos sin la necesidad de una conexión constante a Internet o depender de servicios en la nube. La gestión de modelos lingüísticos locales grandes (LLM) es una característica fundamental de Olama.
Es compatible con muchos modelos de lenguaje de código abierto de gran tamaño, incluido DeepSeek-R1, y es compatible con múltiples plataformas, como macOS, Windows y Linux. Además, ofrece una configuración sencilla con un mínimo de complicaciones y un uso eficiente de los recursos. Ollama te permite aprovechar el poder de la inteligencia artificial directamente en tu dispositivo.
ImportanteAsegúrese de que su máquina local tenga: Accesibilidad de la GPU Para Ollama, esto acelera significativamente el rendimiento y hace que las evaluaciones comparativas posteriores sean más eficientes en comparación con la CPU. Ejecutar el comando
nvidia-smiEn la terminal para comprobar si se detecta la GPU. Este procedimiento asegura que se maximicen las capacidades del dispositivo para ejecutar modelos con alta eficiencia.
(ii) Biblioteca simple-evals de OpenAI para evaluar modelos de lenguaje
Preparar evaluaciones simples Una biblioteca liviana diseñada para evaluar modelos de lenguaje utilizando una metodología de evaluación de cero disparos con estímulos de cadena de pensamiento. Esta biblioteca incluye puntos de referencia de evaluación populares como MMLU, MATH, GPQA, MGSM y HumanEval, y tiene como objetivo simular escenarios de uso del mundo real para evaluar el desempeño de los modelos de IA en tareas de inferencia complejas.
Algunos de ustedes pueden estar familiarizados con la biblioteca de evaluación más popular y completa de OpenAI llamada Evaluaciones, que es diferente de simple-evals.
De hecho, la página indica README La especificación simple-evals indica que no pretende reemplazar la biblioteca. Evaluaciones.
Entonces, ¿por qué utilizamos evaluaciones simples?
La respuesta simple es que evaluaciones simples Viene con textos de evaluación integrados para los estándares de inferencia a los que apuntamos (como GPQA), de los cuales carece la biblioteca. Evaluaciones.
Además, no he encontrado ninguna otra herramienta o plataforma, aparte de simple-evals, que proporcione una forma directa y nativa en el lenguaje. Python Para ejecutar muchos estándares importantes, como GPQA, especialmente cuando se trabaja con Ollama.
(7) Resultados de la evaluación
Como parte de la evaluación, seleccioné: 20 preguntas al azar Del conjunto de preguntas GPQA-Diamond de 198 preguntas para trabajar Formulario 14B Destilador. En total, se necesitaron 216 minutos, o aproximadamente 11 minutos por pregunta.
El resultado fue un tanto decepcionante, ya que registró un 10% Solamente que es significativamente menor que el resultado reportado de 73.3% para el modelo 1B DeepSeek-R671.
El principal problema que noté es que durante el razonamiento interno intensivo, El modelo a menudo no producía ninguna respuesta (por ejemplo, devolvía códigos de inferencia como líneas finales de salida) o proporcionaba una respuesta que no coincidía con el formato de opción múltiple esperado (por ejemplo, respuesta: A).
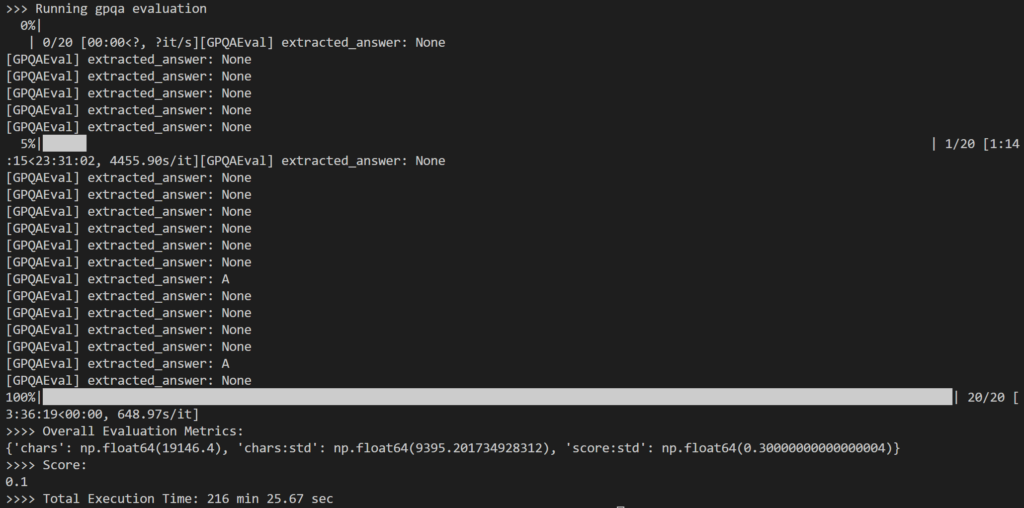
Como se muestra arriba, muchos de los resultados terminaron como: None Porque la lógica de expresiones regulares en simple-evals no pudo detectar el patrón de respuesta esperado en la respuesta LLM.
Considerando que razonamiento similar al humano Fue interesante observarlo, ya que esperaba un desempeño más fuerte en términos de precisión al responder las preguntas.
También he visto a usuarios en línea mencionar que incluso el modelo 32B más grande no funciona tan bien como el o1. Esto ha generado dudas sobre la utilidad de los modelos de inferencia destilados, especialmente cuando tienen dificultades para proporcionar respuestas correctas a pesar de generar inferencias largas.
Sin embargo, GPQA-Diamond es un punto de referencia muy exigente, por lo que estos modelos aún pueden ser útiles para tareas de inferencia más simples. Sus menores requerimientos computacionales también lo hacen más fácil.
Además, el equipo de DeepSeek recomendó ejecutar múltiples pruebas y promediar los resultados como parte del proceso de evaluación comparativa, algo que pasé por alto debido a limitaciones de tiempo.
(8) Guía detallada paso a paso
Hasta este punto hemos cubierto los conceptos básicos y las principales conclusiones.
Si está listo para una experiencia técnica práctica, esta sección proporciona una mirada en profundidad a los mecanismos internos y la implementación paso a paso. Esta guía técnica práctica le proporcionará una comprensión integral de cómo funciona el sistema.
Para ver (o copiar) Repositorio complementario de GitHub A seguir. Los requisitos de configuración del entorno virtual se pueden encontrar aquí. aquí.
(i) Configuración inicial – Ollama
Comenzamos descargando Ollama. Visita
Página de descarga de Ollama, elija su sistema operativo y siga las instrucciones de instalación correspondientes.
Una vez completada la instalación, inicie Ollama haciendo doble clic en la aplicación Ollama (para Windows y macOS) o ejecutando el comando ollama serve En la terminal.
(ii) Configuración inicial – OpenAI simple-evals
La configuración de evaluaciones simples es relativamente única.
Si bien simple-evals se presenta como una biblioteca, La ausencia de archivos __init__.py En el repositorio significa que no está estructurado como un paquete de Python adecuado., lo que genera errores de importación después de clonar el repositorio localmente. Esto significa que no es un paquete Python estándar en el sentido en que se usa comúnmente en ingeniería de software.
Dado que tampoco está publicado en PyPI y carece de archivos de empaquetado estándar como setup.py O pyproject.tomlNo se puede instalar a través de pip. Esto supone un desafío para los nuevos desarrolladores.
Afortunadamente, podemos utilizar Submódulos de Git Como solución alternativa directa. Estos módulos permiten incluir un repositorio Git dentro de otro, facilitando la gestión de dependencias.
“`html
Un submódulo Git nos permite incluir el contenido de otro repositorio Git dentro de nuestro proyecto. Extrae archivos de un repositorio externo (como simple-evals), pero mantiene su historial separado.
Puede elegir uno de dos métodos (A o B) para extraer el contenido de simple-evals:
(a) Si clonas el repositorio de mi proyecto
Mi repositorio de proyectos ya incluye simple-evals Como submódulo, puedes simplemente ejecutar:
git submodule update --init --recursive(b) Si lo está agregando a un proyecto recién creado.
Para agregar manualmente simple-evals como un submódulo, ejecute lo siguiente:
git submodule add https://github.com/openai/simple-evals.git simple_evalsملاحظة: eso simple_evals Al final (con subrayar) es muy importante. Especifica el nombre de la carpeta, utilizando un guión en su lugar (es decir, simple).–Las evaluaciones pueden ocasionar problemas de importación más adelante.
Paso final (para ambos métodos)
Después de extraer el contenido del repositorio, debe crear un archivo. __init__.py Vaciar en carpeta simple_evals El recién creado se puede importar como una unidad. Puedes crearlo manualmente o utilizar el siguiente comando:
touch simple_evals/__init__.py(iii) Extrayendo el modelo DeepSeek-R1 a través de Ollama
El siguiente paso es descargar el modelo destilado localmente de su elección (por ejemplo, 14B) usando este comando:
Puede encontrar una lista de los modelos DeepSeek-R1 disponibles en Ollama. aquí. Para obtener el mejor rendimiento, se recomienda utilizar la última versión de la plantilla.
ollama pull deepseek-r1:14b(Cuarto) Especificar la configuración
Definimos los parámetros en el archivo YAML de configuración, como se muestra a continuación:
# config/config.yaml MODEL_NAME: "deepseek-r1:14b" # Nombre del modelo (coincide con la lista de modelos de Ollama) MODEL_TEMPERATURE: 0.6 # Establezca entre 0.5 y 0.7 para DeepSeek-R1 EVAL_BENCHMARK: "gpqa" GPQA_VARIANT: "diamond" EVAL_N_EXAMPLES: 20
La temperatura del modelo se establece en 0.6 (Comparado con el valor predeterminado típico de 0). Esto sigue las recomendaciones de uso de DeepSeek, que sugieren un rango de temperatura de 0.5 a 0.7 (se recomienda 0.6). Para evitar repeticiones infinitas o resultados incoherentes. Esta configuración es necesaria para mejorar la calidad de la salida y garantizar su consistencia.
No pierdas la oportunidad de comprobarlo Recomendaciones de uso únicas e interesantes de DeepSeek-R1 – especialmente para puntos de referencia – para garantizar un rendimiento óptimo al utilizar modelos DeepSeek-R1.
EVAL_N_EXAMPLES Este es el parámetro utilizado para establecer el número de preguntas del conjunto completo de 198 preguntas utilizadas en la evaluación. Este parámetro es necesario para ajustar el proceso de evaluación según los recursos disponibles y los objetivos específicos de la prueba.
(v) Configuración del código Sampler
Para admitir los modelos de lenguaje basados en Ollama dentro del marco de evaluación simple, creamos una clase contenedora personalizada denominada OllamaSampler Y guárdalo dentro utils/samplers/ollama_sampler.py. Sampler es un componente esencial para probar y evaluar el rendimiento de los modelos de lenguaje.
# utils/samplers/ollama_sampler.py import ollama clase OllamaSampler: def __init__(self, nombre_del_modelo=Ninguno, temperatura=0): self.nombre_del_modelo = nombre_del_modelo self.temperatura = temperatura def __call__(self, mensajes_del_aviso): texto_del_aviso = mensajes_del_aviso[-1]["contenido"] respuesta = ollama.chat( modelo=self.nombre_del_modelo, mensajes=[{"rol": "usuario", "contenido": texto_del_aviso}], opciones={"temperatura": self.temperatura} ) contenido_de_respuesta = respuesta["mensaje"]["contenido"] return contenido_de_respuesta def _pack_message(self, contenido, rol): return {"rol": rol, "contenido": contenido}
En este contexto, significa dechado (Amplificador) Una clase de Python que genera salida a partir de un modelo de lenguaje basado en una solicitud dada. Esta herramienta es crucial para garantizar que se generen respuestas diversas y representativas a partir del modelo.
Dado que los muestreadores en simple-evals solo cubren proveedores como OpenAI y Claude, necesitamos una clase de muestreador que proporcione una interfaz compatible con Ollama. Esto garantiza una integración perfecta con el marco de evaluación.
Usted OllamaSampler Extrae una pregunta GPQA, la envía al formulario a una temperatura específica y devuelve una respuesta de texto sin formato. La temperatura es un parámetro importante que controla la aleatoriedad de la salida.
Método incluido _pack_message Para garantizar que el formato de salida coincida con lo que esperan los scripts de evaluación en simple-evals. Esto garantiza la coherencia y la facilidad del análisis.
6. Crear un guión de evaluación
El siguiente código demuestra cómo configurar la implementación de la evaluación en un archivo. main.py, incluido el uso de la categoría GPQAEval Desde la biblioteca simple-evals para ejecutar pruebas comparativas GPQA.
Función run_eval() Es una herramienta de ejecución de evaluación configurable que prueba modelos de lenguaje grandes (LLM) a través de Ollama contra estándares como GPQA. Esta función es necesaria para evaluar con precisión el rendimiento de los modelos.
# main.py def run_eval(): start_time = time.time() # Cargar archivo de configuración config = load_config("config/config.yaml") # Inicializar el sampler de Ollama (envoltorio alrededor del chat de Ollama) ollama_sampler = OllamaSampler(model_name=config["MODEL_NAME"], temperatures=config["MODEL_TEMPERATURE"] ) # Seleccionar la clase de evaluación a usar según EVAL_BENCHMARK eval_benchmark = config["EVAL_BENCHMARK"] # GPQA print(f">>> Ejecutando la evaluación {eval_benchmark}") if eval_benchmark == "gpqa": eval_class = GPQAEval eval_kwargs = { "n_repeats": config["EVAL_N_REPEATS"], # Predeterminado 1 "num_examples": config["EVAL_N_EXAMPLES"], # Establecer en 20 "variant": config["GPQA_VARIANT"], # Subconjunto GPQA-Diamond } else: raise ValueError( f"Unknown EVAL_BENCHMARK '{eval_benchmark}'." ) # Instanciar y ejecutar la evaluación apropiada evaluator = eval_class(**eval_kwargs) results = evaluator(ollama_sampler) # Ejecutar la evaluación con el muestreador end_time = time.time() elapsed_seconds = end_time - start_time minutes, seconds = divmod(elapsed_seconds, 60) # Calcular el tiempo total empleado # Los resultados devueltos son un EvalResult que incluye una lista de SingleEvalResult y métricas agregadas print(">>>> Métricas de evaluación generales:", results.metrics) print(">>>> Puntuación:", results.score) print(f">>>> Tiempo total de ejecución: {int(minutos)} min {segundos:.2f} sec") si __name__ == "__main__": # Ejecutar la ejecución de la evaluación GPQA run_eval()
La función carga las configuraciones del archivo de configuración, configura la clase de evaluación adecuada desde simple-evals y ejecuta el modelo a través de un proceso de evaluación uniforme. Se guarda en un archivo. main.py, que se puede ejecutar usando el comando python main.py. Esto garantiza un proceso de evaluación consistente y repetible.
Siguiendo los pasos anteriores, hemos configurado y ejecutado con éxito el punto de referencia GPQA-Diamond en el modelo destilado DeepSeek-R1. Este proceso proporciona información valiosa sobre las capacidades del modelo.
La línea de fondo
En este artículo, exploramos cómo podemos combinar herramientas como Ollama y simple-evals de OpenAI para explorar y evaluar modelos extraídos de DeepSeek-R1, con un enfoque en Evaluación del rendimiento de modelos lingüísticos de gran tamaño.
Es posible que los modelos destilados aún no coincidan con el modelo original de 671 mil millones de parámetros en puntos de referencia de inferencia desafiantes como GPQA-Diamond. Sin embargo, sí ilustra cómo la destilación puede ampliar el acceso a las capacidades de inferencia de los modelos de lenguaje grandes (LLM). Mejorar el acceso a modelos lingüísticos de gran tamaño Es un objetivo importante en este ámbito.
A pesar del menor rendimiento en tareas complejas de nivel de doctorado, estas variantes más pequeñas aún pueden ser aplicables en escenarios menos exigentes, allanando el camino para una implementación local eficiente en una gama más amplia de dispositivos. Esto contribuye a Implementar modelos de lenguaje grandes localmente Eficientemente.
Los comentarios están cerrados.