

Lograr certeza en modelos de lenguaje grandes (LLM) utilizando circuitos inteligentes de toma de decisiones
La incertidumbre no es algo nuevo en la tecnología: todos los sistemas modernos superan las entradas y salidas inciertas utilizando estructuras de control probadas matemáticamente.
La promesa de los agentes de IA ha conquistado al mundo. Los agentes pueden interactuar con el mundo que los rodea, escribir artículos (pero no este), tomar acciones en su nombre y, en general, hacer que la parte difícil de automatizar cualquier tarea sea fácil y accesible.
Los agentes se centran en las partes más difíciles de las operaciones y resuelven los problemas rápidamente. A veces demasiado rápido: si su proceso basado en agentes requiere que haya un humano en el circuito para decidir el resultado, la etapa de revisión humana puede convertirse en un cuello de botella en el proceso.
Un ejemplo de un proceso basado en agentes es el procesamiento y la clasificación de las llamadas telefónicas de los clientes. Incluso un agente con un 99.95% de precisión cometerá 5 errores al escuchar 10,000 llamadas. A pesar de saber esto, el agente no te lo puede decir. Es decir 5 de cada 10,000 llamadas fueron clasificadas erróneamente.

La técnica “LLM como juez” es una técnica en la que se introduce cada entrada en otro proceso LLM para evaluar si la salida que proviene de la entrada es correcta. Sin embargo, dado que se trata de otro proceso de LLM, también puede ser inexacto. Estas dos operaciones probabilísticas crean una matriz de confusión con verdaderos positivos, falsos negativos, verdaderos negativos y falsos positivos.
En otras palabras, una entrada que es clasificada correctamente por un proceso LLM puede ser juzgada como incorrecta por su juez LLM o viceversa.
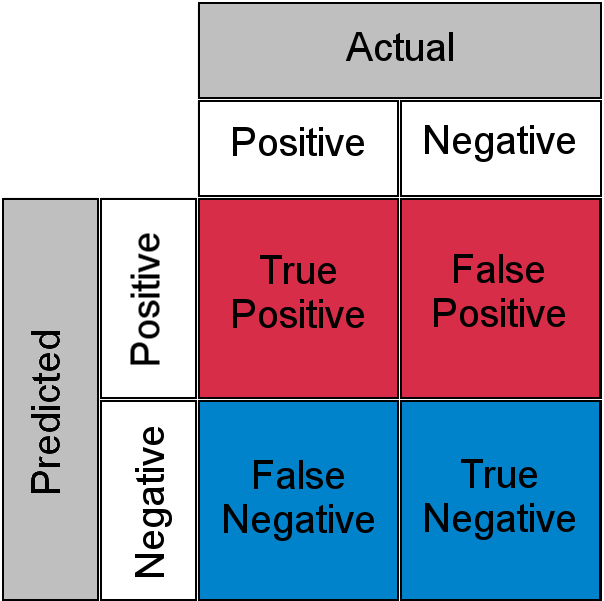
Debido a esto " Lo desconocido conocido Para una carga de trabajo sensible, una persona tiene que revisar y comprender las 10,000 XNUMX llamadas. Volvemos al mismo problema de cuello de botella.
¿Cómo podemos incorporar mayor certeza estadística a nuestros procesos basados en agentes? En esta publicación, desarrollo un sistema que nos permite aumentar la certeza en nuestros procesos basados en agentes, lo generalizo a un número arbitrario de agentes y desarrollo una función de costos para orientar futuras inversiones en el sistema. El código que utilizo en esta publicación está disponible en mi repositorio. circuitos de decisión de IA.
Circuitos de toma de decisiones de IA
Detectar y corregir errores no son conceptos nuevos. La corrección de errores es crucial en campos como la electrónica digital y analógica. Incluso los avances en la computación cuántica dependen de la ampliación de las capacidades de detección y corrección de errores. Podemos inspirarnos en estos sistemas e implementar algo similar con agentes de IA. Por ejemplo, puedes Algoritmos de inteligencia artificial Utilización avanzada de técnicas de corrección de errores encontradas en los sistemas de comunicación.
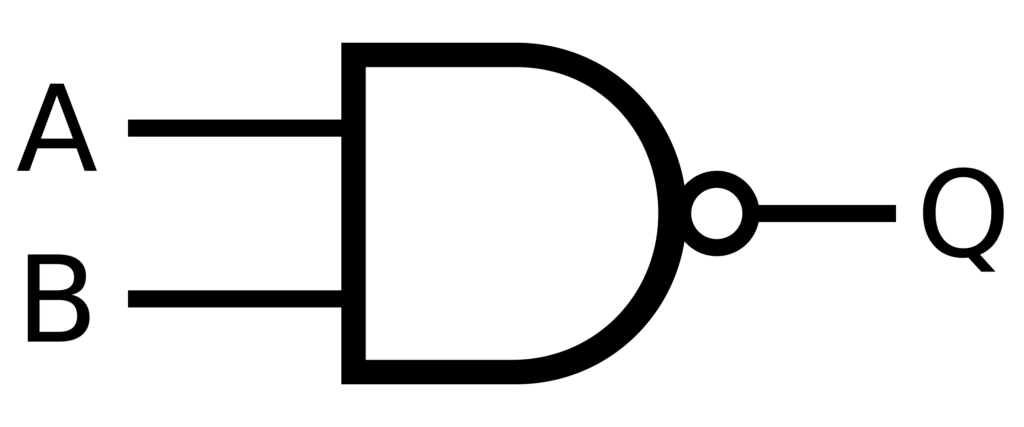
En la lógica booleana, las puertas NAND son el santo grial de la computación porque pueden realizar cualquier operación. Es funcionalmente completo, lo que significa que cualquier operación lógica se puede crear utilizando sólo puertas NAND. Este principio se puede aplicar a los sistemas de IA para crear estructuras de toma de decisiones sólidas con corrección de errores incorporada. Esto permite la creación de redes neuronales Más confiable y capaz de manejar datos incompletos o ruidosos.
De circuitos electrónicos a circuitos de toma de decisiones inteligentes (IA)
Así como los circuitos electrónicos utilizan la repetición y la verificación para garantizar cálculos confiables, los circuitos de toma de decisiones inteligentes (IA) pueden utilizar múltiples agentes con diferentes perspectivas para llegar a resultados más precisos. Estos circuitos se pueden construir utilizando principios de la teoría de la información y la lógica booleana:
- Procesamiento redundante: Varios agentes de IA procesan las mismas entradas de forma independiente, de forma similar a cómo las CPU modernas utilizan circuitos redundantes para detectar errores de hardware. Este proceso aumenta la confiabilidad del sistema de IA.
- Mecanismos de consenso: Los resultados de las decisiones se combinan utilizando sistemas de votación o promedios ponderados, similares a las puertas lógicas mayoritarias en la electrónica tolerante a fallas. Estos mecanismos garantizan que la decisión final refleje el consenso entre los agentes.
- Agentes validadores: Los auditores de IA especializados verifican la razonabilidad del resultado y funcionan de manera similar a los códigos de detección de errores como Bits de paridad O comprobaciones de redundancia cíclica (comprobaciones CRC). Estos agentes reducen la probabilidad de tomar decisiones equivocadas.
- Integración humana en el circuito: Verificación humana estratégica en puntos clave del proceso de toma de decisiones, similar a cómo los sistemas biométricos utilizan la supervisión humana como capa de verificación final. Esto garantiza que las decisiones importantes estén sujetas a la evaluación humana.
Fundamentos matemáticos de los circuitos de toma de decisiones en inteligencia artificial
La confiabilidad de estos sistemas se puede determinar cuantitativamente utilizando la teoría de probabilidad.
Por un lado, la probabilidad de falla proviene de la precisión observada a lo largo del tiempo en un conjunto de datos de prueba, almacenados en un sistema como LangSmith.

Para un factor de precisión del 90%, la probabilidad de falla, p_1، 1–0.9 Es 0.1, o 10%.

La probabilidad de que dos factores independientes fallen en la misma entrada es la probabilidad de que ambos factores sean precisos multiplicada entre sí:
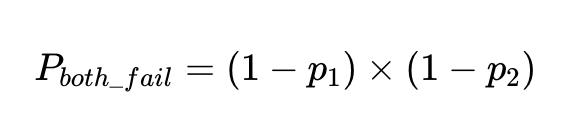
Si tenemos N ejecuciones con estos clientes, el número total de fallos es
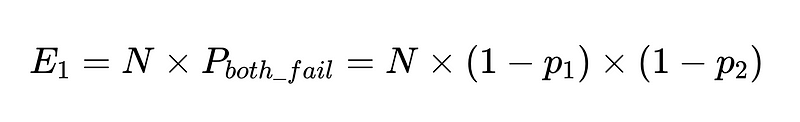
Entonces, para 10,000 ejecuciones entre dos trabajadores independientes con un 90% de precisión, el número esperado de fallas es 100.
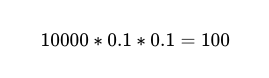
Sin embargo, todavía no lo sabemos. Es decir De esas 10,000 llamadas telefónicas, 100 son fracasos reales.
Podemos combinar cuatro extensiones de esta idea para proporcionar una solución más sólida que brinde confianza en cualquier respuesta dada:
- Clasificador básico (resolución simple arriba)
- Copia de seguridad (resolución simple arriba)
- Comprobador de esquemas (resolución 0.7 por ejemplo)

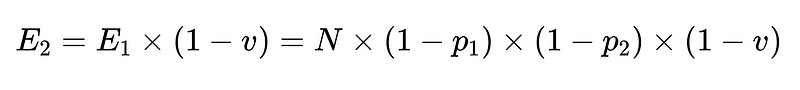
- Finalmente, un validador negativo (n = precisión 0.6 por ejemplo)
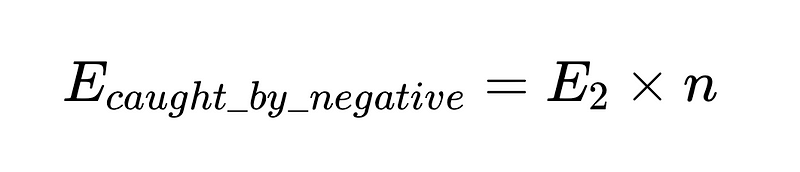
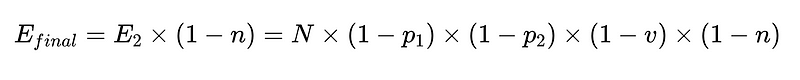
Para poner esto en código (El almacén completo), podemos utilizar Python básico:
def primary_parser(self, customer_input: str) -> Dict[str, str]:
"""
Primary parser: Direct command with format expectations.
"""
prompt = f"""
Extract the category of the customer service call from the following text as a JSON object with key 'call_type'.
The call type must be one of: {', '.join(self.call_types)}.
If the category cannot be determined, return {{'call_type': null}}.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
try:
# Try to parse the response as JSON
result = json.loads(response.content.strip())
return result
except json.JSONDecodeError:
# If JSON parsing fails, try to extract the call type from the text
for call_type in self.call_types:
if call_type in response.content:
return {"call_type": call_type}
return {"call_type": None}
def backup_parser(self, customer_input: str) -> Dict[str, str]:
"""
Backup parser: Chain of thought approach with formatting instructions.
"""
prompt = f"""
First, identify the main issue or concern in the customer's message.
Then, match it to one of the following categories: {', '.join(self.call_types)}.
Think through each category and determine which one best fits the customer's issue.
Return your answer as a JSON object with key 'call_type'.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
try:
# Try to parse the response as JSON
result = json.loads(response.content.strip())
return result
except json.JSONDecodeError:
# If JSON parsing fails, try to extract the call type from the text
for call_type in self.call_types:
if call_type in response.content:
return {"call_type": call_type}
return {"call_type": None}
def negative_checker(self, customer_input: str) -> str:
"""
Negative checker: Determines if the text contains enough information to categorize.
"""
prompt = f"""
Does this customer service call contain enough information to categorize it into one of these types:
{', '.join(self.call_types)}?
Answer only 'yes' or 'no'.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
answer = response.content.strip().lower()
if "yes" in answer:
return "yes"
elif "no" in answer:
return "no"
else:
# Default to yes if the answer is unclear
return "yes"
@staticmethod
def validate_call_type(parsed_output: Dict[str, Any]) -> bool:
"""
Schema validator: Checks if the output matches the expected schema.
"""
# Check if output matches expected schema
if not isinstance(parsed_output, dict) or 'call_type' not in parsed_output:
return False
# Verify the extracted call type is in our list of known types or null
call_type = parsed_output['call_type']
return call_type is None or call_type in CALL_TYPESAl combinar estas operaciones con la lógica, Boolean En pocas palabras, podemos obtener una precisión similar y confianza en cada respuesta:
def combine_results(
primary_result: Dict[str, str],
backup_result: Dict[str, str],
negative_check: str,
validation_result: bool,
customer_input: str
) -> Dict[str, str]:
"""
Combiner: Combines the results from different strategies.
"""
# If validation failed, use backup
if not validation_result:
if RobustCallClassifier.validate_call_type(backup_result):
return backup_result
else:
return {"call_type": None, "confidence": "low", "needs_human": True}
# If negative check says no call type can be determined but we extracted one, double-check
if negative_check == 'no' and primary_result['call_type'] is not None:
if backup_result['call_type'] is None:
return {'call_type': None, "confidence": "low", "needs_human": True}
elif backup_result['call_type'] == primary_result['call_type']:
# Both agree despite negative check, so go with it but mark low confidence
return {'call_type': primary_result['call_type'], "confidence": "medium"}
else:
return {"call_type": None, "confidence": "low", "needs_human": True}
# If primary and backup agree, high confidence
if primary_result['call_type'] == backup_result['call_type'] and primary_result['call_type'] is not None:
return {'call_type': primary_result['call_type'], "confidence": "high"}
# Default: use primary result with medium confidence
if primary_result['call_type'] is not None:
return {'call_type': primary_result['call_type'], "confidence": "medium"}
else:
return {'call_type': None, "confidence": "low", "needs_human": True}
Lógica de decisión: una explicación paso a paso
Paso 1: Cuando falla el sistema de control de calidad
if not validation_result:Esto significa: “Si nuestro experto en control de calidad (auditor) rechaza el análisis inicial, no confíe en él”. El sistema luego intenta utilizar la opinión de respaldo. Si esto también falla la verificación, marca el caso para que lo revise un especialista humano. Este procedimiento garantiza que no confíe en datos inexactos.
En pocas palabras: «Si algo no cuadra con nuestra primera respuesta, probemos con nuestro método alternativo. Si aún es cuestionable, pidamos la intervención de un experto». Esto garantiza que los casos complejos se manejen correctamente.
Paso 2: Abordar las discrepancias
if negative_check == 'no' and primary_result['call_type'] is not None:Este paso verifica un tipo específico de discrepancia: “Nuestro verificador negativo indica que no debería haber un tipo de compra, pero nuestro analista fundamental encontró un tipo de venta de todos modos”.
En tales casos, el sistema depende del analista de respaldo para alcanzar el punto de equilibrio:
- Si el analista de respaldo acepta que no existe ningún tipo de llamada, se envía al elemento humano.
- Si el analista de respaldo está de acuerdo con el analista principal, entonces se acepta, pero con confianza media.
- Si el analista de respaldo tiene un tipo de llamada diferente ← se envía al elemento humano
Esto es como decir: “Si un experto dice ‘esto es inclasificable’ pero otro dice que sí, necesitamos un desempate o un juez humano”. Este mecanismo es necesario para garantizar una clasificación precisa del tipo de llamada y reducir posibles errores.
Paso 3: Cuando los expertos están de acuerdo
if primary_result['call_type'] == backup_result['call_type'] and primary_result['call_type'] is not None:Cuando los analistas principales y de respaldo llegan independientemente a la misma conclusión, el sistema la marca como de “alta confianza”, este es el mejor escenario. Esta situación ideal ocurre cuando múltiples análisis son concluyentemente consistentes.
En términos simples: “Si dos expertos diferentes que utilizan métodos diferentes llegan independientemente a la misma conclusión, podemos estar bastante seguros de que su conclusión es correcta”. Esto representa el consenso de los expertos, lo cual es un fuerte indicador de precisión y confiabilidad.
Paso 4: Procesamiento predeterminado
Si no se aplica ninguna de las condiciones especiales, el sistema adopta de manera predeterminada el resultado del analista principal con confianza “media”. Si el analista principal no puede identificar el tipo de llamada, marca el caso para que lo revise un analista humano especializado.
La importancia de este enfoque para reducir errores
Esta lógica contribuye a construir un sistema fuerte al:
- Reducir los falsos positivosEl sistema solo ofrece un alto nivel de confianza cuando varios métodos coinciden, lo que reduce en gran medida las falsas alarmas.
- Descubriendo contradiccionesCuando las distintas partes del sistema difieren, se reduce la confianza o se escala el asunto a revisores humanos, lo que garantiza que no se pase por alto ningún problema potencial.
- Escalada inteligenteLos revisores humanos solo ven casos que realmente necesitan su experiencia, lo que aumenta la eficiencia del proceso de revisión y reduce el estrés de los recursos humanos.
- Designación de fideicomisoLos resultados incluyen el nivel de confianza del sistema, lo que permite que los procesos posteriores traten los resultados de alta confianza frente a los de confianza media de manera diferente, lo que es fundamental para tomar decisiones informadas.
Este enfoque es similar a la forma en que la electrónica utiliza circuitos redundantes y mecanismos de votación para evitar que los errores provoquen fallas del sistema. En los sistemas de IA, este tipo de lógica de integración reflexiva puede reducir significativamente las tasas de error y al mismo tiempo utilizar revisores humanos de manera eficiente solo donde agregan más valor. Esto garantiza que se optimicen los recursos y se reduzcan los errores simultáneamente, lo que da como resultado un sistema más confiable y preciso.
مثال
En 2015, el Departamento de Agua de la Ciudad de Filadelfia publicó Estadísticas de llamadas de clientes por categoría. Comprender las llamadas de los clientes es un proceso muy común que abordan los agentes. En lugar de que una persona escuche cada llamada telefónica de un cliente, un agente puede escuchar la llamada mucho más rápidamente, extraer información y categorizar la llamada para un análisis de datos posterior. Para la gestión del agua, esto es importante porque cuanto antes se identifiquen los problemas críticos, antes podrán resolverse.
Podemos construir una experiencia. Utilicé un modelo de lenguaje grande (LLM) para generar transcripciones falsas de las llamadas telefónicas en cuestión preguntando: “Dada la siguiente clase, genere una versión corta de esa llamada telefónica: A continuación se muestran algunos de estos ejemplos con el archivo completo disponible. aquí:
{
"calls": [
{
"id": 5,
"type": "ABATEMENT",
"customer_input": "I need to report an abandoned property that has a major leak. Water is pouring out and flooding the sidewalk."
},
{
"id": 7,
"type": "AMR (METERING)",
"customer_input": "Can someone check my water meter? The digital display is completely blank and I can't read it."
},
{
"id": 15,
"type": "BTR/O (BAD TASTE & ODOR)",
"customer_input": "My tap water smells like rotten eggs. Is it safe to drink?"
}
]
}Ahora, podemos configurar el experimento con una evaluación más tradicional utilizando un modelo de lenguaje grande como juez (Implementación completa aquí):
def classify(customer_input):
CALL_TYPES = [
"RESTORE", "ABATEMENT", "AMR (METERING)", "BILLING", "BPCS (BROKEN PIPE)", "BTR/O (BAD TASTE & ODOR)",
"C/I - DEP (CAVE IN/DEPRESSION)", "CEMENT", "CHOKED DRAIN", "CLAIMS", "COMPOST"
]
model = ChatAnthropic(model='claude-3-7-sonnet-latest')
prompt = f"""
You are a customer service AI for a water utility company. Classify the following customer input into one of these categories:
{', '.join(CALL_TYPES)}
Customer input: "{customer_input}"
Respond with just the category name, nothing else.
"""
# Get the response from Claude
response = model.invoke(prompt)
predicted_type = response.content.strip()
return predicted_typeAl pasar solo el texto a un modelo de lenguaje grande (LLM), podemos aislar el verdadero conocimiento de clase de la clase extraída que se devuelve y comparar.
def compare(customer_input, actual_type)
predicted_type = classify(customer_input)
result = {
"id": call["id"],
"customer_input": customer_input,
"actual_type": actual_type,
"predicted_type": predicted_type,
"correct": actual_type == predicted_type
}
return resultAl ejecutar esto en todo el conjunto de datos sintéticos utilizando Claude 3.7 Sonnet (el último modelo, al momento de escribir este artículo), se obtiene un rendimiento muy alto, con un 91 % de llamadas clasificadas con precisión:
"metrics": {
"overall_accuracy": 0.91,
"correct": 91,
"total": 100
}Si se tratara de llamadas reales y no tuviéramos conocimiento previo de la categoría, aún necesitaríamos revisar las 100 llamadas telefónicas para encontrar las 9 llamadas mal clasificadas.
Al aplicar nuestro poderoso circuito de toma de decisiones anterior, obtenemos resultados de precisión similares junto con Confianza En esas respuestas. En este caso, una precisión general del 87%, pero una precisión del 92.5% en nuestras respuestas de alta confianza.
{
"metrics": {
"overall_accuracy": 0.87,
"correct": 87,
"total": 100
},
"confidence_metrics": {
"high": {
"count": 80,
"correct": 74,
"accuracy": 0.925
},
"medium": {
"count": 18,
"correct": 13,
"accuracy": 0.722
},
"low": {
"count": 2,
"correct": 0,
"accuracy": 0.0
}
}
}Necesitamos un 100% de precisión en nuestras respuestas de alta confianza, por lo que aún queda trabajo por hacer. Lo que nos permite este enfoque es profundizar en razón Inexactitud de las respuestas de alta confianza. En este caso, las afirmaciones débiles y las capacidades de verificación simples no captan todas las cuestiones, lo que conduce a errores de clasificación. Estas capacidades se pueden mejorar iterativamente para lograr una precisión del 100 % en respuestas de alta confianza.
Mejoras en el sistema de filtrado para aumentar la confianza en los resultados.
El sistema actual clasifica las respuestas como “de alta confianza” cuando los analistas principales y de respaldo están de acuerdo. Para lograr una mayor precisión, debemos ser más selectivos en cuanto a lo que se considera “alta confianza”.
# Modified high confidence logic
if (primary_result['call_type'] == backup_result['call_type'] and
primary_result['call_type'] is not None and
validation_result and
negative_check == 'yes' and
additional_validation_metrics > threshold):
return {'call_type': primary_result['call_type'], "confidence": "high"}Al agregar criterios de calificación adicionales, obtendremos menos resultados de “alta confianza”, pero serán más precisos. Esta mejora en el sistema de filtrado tiene como objetivo reducir errores y aumentar la fiabilidad de los datos clasificados como de alta calidad.
Técnicas de verificación adicionales: mejorando la precisión del análisis
A continuación se presentan algunas otras ideas para mejorar su proceso de validación y análisis de datos:
Analizador terciarioAñadir un tercer método de análisis independiente. Este método sirve como una capa adicional de verificación, comparando los resultados de dos métodos analíticos diferentes con el resultado de un tercer método, para garantizar una mayor precisión y reducir la posibilidad de errores.
# Only mark high confidence if all three agree
if primary_result['call_type'] == backup_result['call_type'] == tertiary_result['call_type']:Coincidencia de patrones históricos:Compare los resultados con resultados históricamente correctos (piense en una búsqueda vectorial). Esta técnica utiliza datos históricos confiables como referencia y compara con ellos los resultados actuales para identificar desviaciones o inconsistencias. Puede considerarse una especie de “memoria” para el análisis, ayudando a detectar anomalías o situaciones inesperadas.
if similarity_to_known_correct_cases(primary_result) > 0.95:Pruebas adversariasAplique pequeñas variaciones a las entradas y verifique si la clasificación permanece estable. Este método tiene como objetivo probar la robustez y robustez de un sistema de clasificación exponiéndolo a cambios menores en los datos. Si el sistema es muy sensible a estos cambios, puede indicar posibles debilidades o sesgos.
variations = generate_input_variations(customer_input)
if all(analyze_call_type(var) == primary_result['call_type'] for var in variations):
Fórmula general para intervenciones humanas en un sistema de extracción LLM
La derivación completa está disponible aquí..
- N = Número total de ejecuciones (10,000 XNUMX en nuestro ejemplo)
- p_1 = precisión del analizador base (0.8 en nuestro ejemplo)
- p_2 = precisión del analizador de respaldo (0.8 en nuestro ejemplo)
- v = efectividad del validador de esquema (0.7 en nuestro ejemplo)
- n = efectividad del verificador negativo (0.6 en nuestro ejemplo)
- H = número de intervenciones humanas requeridas
- E_final = errores finales no detectados
- m = número de auditores independientes
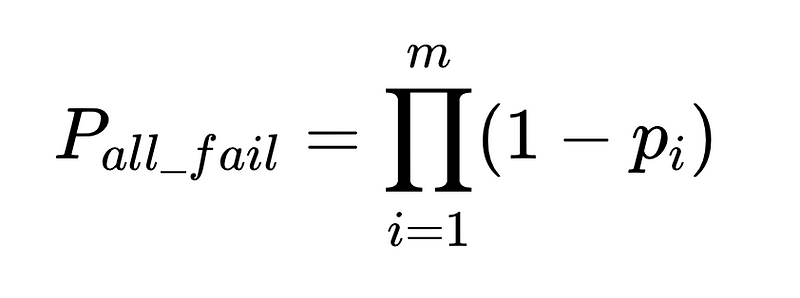
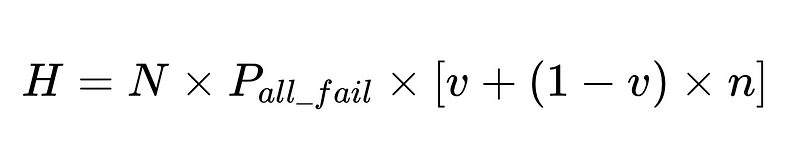
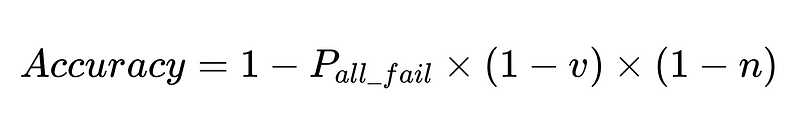
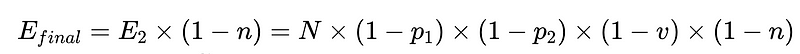
Diseño óptimo del sistema
La ecuación revela información clave sobre la precisión de un sistema de procesamiento del lenguaje natural (PLN):
- Agregar analizadores reduce la sobrecarga pero mejora la precisión general.
- La precisión del sistema está limitada por:
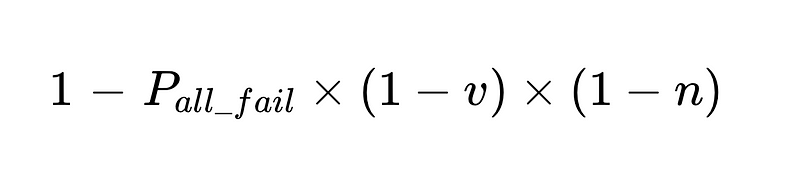
- Las intervenciones humanas son proporcionales Directamente Con un total de N ejecuciones.
por ejemplo:
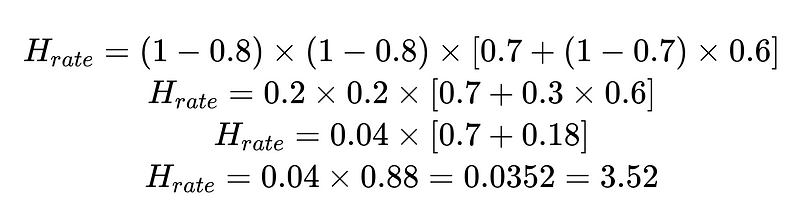
Podemos utilizar la tasa de intervención humana calculada (H_rate) para realizar un seguimiento de la eficacia de nuestra solución en tiempo real. Si la tasa de intervención humana empieza a superar el 3.5%, sabemos que el sistema está fallando. Si la tasa de intervención humana disminuye constantemente a menos del 3.5 %, sabemos que nuestras optimizaciones están funcionando como se espera.
función de costo
También podemos crear una función de costes que nos ayude a mejorar nuestro sistema. La función de costo es una poderosa herramienta analítica para evaluar el desempeño financiero de un sistema e identificar áreas potenciales de mejora.
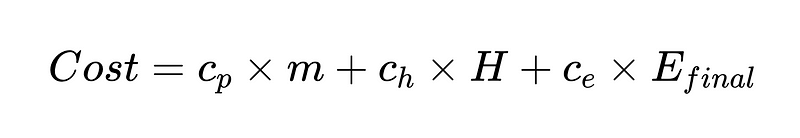
Nombre:
- c_p = costo de ejecución por analizador ($0.10 en nuestro ejemplo)
- m = número de veces que se ejecuta el analizador (en nuestro ejemplo 2 * N)
- H = Número de casos que requieren intervención humana (352 de nuestro ejemplo)
- c_h = costo de una intervención humana ($200 por ejemplo: 4 horas a $50/hora)
- c_e = costo de un error no detectado (por ejemplo, $1000)
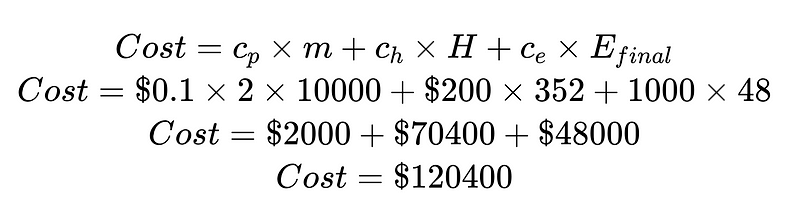
Al dividir el costo entre el costo de la intervención humana y el costo de los errores no detectados, podemos mejorar el sistema en general. En este ejemplo, si el costo de la intervención humana (70,400 48,000 $) es indeseable y costoso, podemos enfocarnos en aumentar la confianza en los resultados. Si el costo de los errores no detectados (XNUMX XNUMX $) es indeseable y costoso, podemos implementar analizadores sintácticos Plus para reducir la tasa de errores no detectados.
Por supuesto, las funciones de costos son más útiles como formas de explorar cómo mejorar las situaciones que describen.
A partir del escenario anterior, para reducir el número de errores no detectados, E_final, en un 50%, donde
- p1 y p2 = 0.8,
- v = 0.7 y
- n = 0.6
Tenemos tres opciones:
- Se ha añadido un nuevo analizador gramatical con una precisión del 50 % como analizador secundario. Tenga en cuenta que esto conlleva una desventaja: el coste de ejecutar los analizadores gramaticales Plus aumenta junto con el mayor coste de la intervención humana.
- Mejorar los analizadores gramaticales existentes en un 10% cada uno. Esto puede o no ser posible debido a la dificultad de la tarea realizada por estos analizadores sintácticos.
- Mejorar el proceso de auditoría en un 15%. Nuevamente esto incrementa el costo debido a la intervención humana.
El futuro de la confianza en la IA: generar confianza mediante precisión extrema
A medida que los sistemas de IA se integran cada vez más en aspectos vitales de los negocios y la sociedad, la búsqueda de una precisión óptima será cada vez más imperativa, especialmente en aplicaciones críticas. Al adoptar estos enfoques inspirados en circuitos para la toma de decisiones de IA, podemos construir sistemas que no solo escalen de manera eficiente, sino que también ganen la confianza profunda que solo proviene de un desempeño constante y confiable. El futuro no está en modelos individuales más poderosos, sino en sistemas cuidadosamente diseñados que combinen múltiples perspectivas con supervisión humana estratégica.
Así como la electrónica digital evolucionó a partir de componentes poco confiables para crear computadoras en las que confiamos nuestros datos más importantes, los sistemas de IA ahora están en un viaje similar. Los marcos descritos en este artículo representan los modelos de lo que eventualmente se convertirá en la arquitectura estándar para la IA de misión crítica: sistemas que no solo prometen confiabilidad, sino que la garantizan matemáticamente. La pregunta ya no es si podemos construir sistemas de IA con una precisión casi perfecta, sino con qué rapidez podemos implementar estos principios en nuestras aplicaciones más importantes.
Los comentarios están cerrados.