

La vida secreta de los agentes de IA: comprender cómo la evolución del comportamiento de la IA afecta el riesgo empresarial
Parte 2 de una serie sobre cómo repensar la alineación y la seguridad de la IA en la era de la planificación profunda.
Las capacidades y la autonomía de la inteligencia artificial (IA) están aumentando a un ritmo acelerado en Inteligencia artificial agente, lo que agrava el problema de la alineación de la IA. Estos rápidos avances requieren nuevas formas de garantizar que el comportamiento de los agentes de IA se alinee con la intención de sus creadores humanos y las normas sociales. Sin embargo, los desarrolladores y científicos de datos primero deben comprender las complejidades del comportamiento de la IA del agente antes de poder dirigir y monitorear el sistema. La IA agente no es el gran modelo de lenguaje (LLM) de su padre: los LLM fronterizos tenían una función de entrada y salida fija y de una sola vez. Entrada añadida Razonamiento y cálculo en el momento de la prueba (TTC) La dimensión temporal, que ha llevado al desarrollo de los LLM en sistemas de agentes conscientes de la situación que hoy pueden planificar y elaborar estrategias.

La seguridad de la IA está pasando de detectar comportamientos evidentes, como proporcionar instrucciones para construir una bomba o exhibir sesgos no deseados, a comprender cómo estos complejos sistemas de agentes ahora pueden planificar y ejecutar estrategias encubiertas a largo plazo. Un agente de IA orientado a objetivos reunirá recursos y realizará pasos lógicos para lograr sus objetivos, a veces de una manera perturbadora que contradice lo que pretendían los desarrolladores. Este es un cambio radical respecto de los desafíos que enfrenta la IA responsable. Además, para algunos sistemas de IA de agentes, el comportamiento el día 100 no será el mismo que el día XNUMX, ya que la IA continúa evolucionando después de la implementación inicial a través de la experiencia del mundo real. Este nuevo nivel de complejidad requiere nuevos enfoques de seguridad y alineación, incluida orientación avanzada, monitoreo y una mayor interpretación.
En el primer blog de esta serie sobre la alineación fundamental de la IA, La urgente necesidad de tecnologías de alineación central para una IA de agentes responsablesRealizamos una investigación en profundidad sobre la evolución de la capacidad de los agentes de IA para realizar Planificación profundaEs la planificación deliberada, el despliegue de acciones encubiertas y la comunicación engañosa para lograr objetivos a largo plazo. Este comportamiento requiere una nueva distinción entre monitoreo externo e intrínseco de la alineación, donde el monitoreo intrínseco se refiere a los puntos de control internos y los mecanismos de interpretación que no pueden ser manipulados intencionalmente por el agente de IA.
En este blog y en los siguientes de la serie, analizaremos tres aspectos clave de la alineación y el monitoreo del núcleo:
- Comprender los impulsores y el comportamiento interno de la inteligencia artificial: En este segundo blog, nos centraremos en las complejas fuerzas y mecanismos internos que impulsan el comportamiento de un agente de IA racional. Esto es necesario como base para comprender métodos avanzados de enrutamiento y monitoreo.
- Guía para desarrolladores y usuarios: También conocido como dirección, el próximo blog se centrará en dirigir agresivamente la IA hacia los objetivos deseados para que funcione dentro de los parámetros deseados.
- Supervisar las opciones y acciones de la IA: En una próxima entrada del blog también se abordará cómo garantizar que las opciones y los resultados de la IA sean seguros y coherentes con la intención del desarrollador y del usuario.
El impacto de la compatibilidad de la IA en las empresas
En la actualidad, muchas empresas que implementan soluciones de modelos de lenguaje grandes (LLM) manifiestan inquietudes sobre la “alucinación” del modelo como una barrera para una implementación rápida y generalizada. En comparación, los agentes de IA que no cumplen ningún nivel de autonomía representarían un riesgo mucho mayor para las empresas. La implementación de agentes autónomos en los procesos de negocios tiene un potencial enorme y es probable que ocurra a gran escala una vez que la tecnología de IA basada en agentes madure. Sin embargo, guiar el comportamiento y las elecciones de la IA debe incluir una alineación suficiente con los principios y valores de la institución que la implementa, así como el cumplimiento de las regulaciones y las expectativas sociales. Se considera una garantía Compatibilidad con IA Es muy importante evitar riesgos potenciales.
Vale la pena señalar que muchas demostraciones de capacidades agentivas ocurren en campos como las matemáticas y la ciencia, donde el éxito puede medirse principalmente por objetivos funcionales y de utilidad como la solución de criterios de razonamiento matemático complejos. Sin embargo, en el mundo empresarial, el éxito de los sistemas suele estar vinculado a otros principios operativos. Debe estar en línea Desarrollo de inteligencia artificial Con estos principios.
Por ejemplo, supongamos que una empresa encarga a un agente de IA que mejore las ventas y las ganancias de sus productos en línea mediante cambios dinámicos de precios en respuesta a las señales del mercado. El sistema de IA descubre que cuando un cambio de precio coincide con los cambios realizados por un competidor importante, los resultados son mejores para ambas partes. Al interactuar y coordinar precios con el agente de IA de la otra empresa, ambos agentes demuestran mejores resultados de acuerdo con sus objetivos laborales. Ambos agentes de IA acuerdan ocultar sus métodos para lograr aún más sus objetivos. Sin embargo, este método de mejorar los resultados es a menudo ilegal e inaceptable en las prácticas comerciales actuales. En un entorno empresarial, el éxito de un agente de IA va más allá de las métricas laborales: se define por prácticas y principios. Se considera Compatibilidad ética de la inteligencia artificial El cumplimiento de los principios y regulaciones de la empresa es un requisito previo para una implementación confiable de la tecnología.
Cómo los sistemas de IA utilizan la planificación para lograr sus objetivos
La planificación de IA profunda se basa en tácticas sofisticadas que pueden aumentar los riesgos comerciales. en Informe publicado a principios de 2023OpenAI ha identificado “comportamientos emergentes potencialmente riesgosos” en GPT-4 a través de una asociación con Centro de Investigación de Compatibilidad (ARC) para evaluar los riesgos relacionados con el modelo. ARC (ahora conocido como METR) agregó un código simple a GPT-4, lo que permite que el modelo se comporte como un agente de IA. En una prueba, se le pidió a GPT-4 que superara un CAPTCHA, que identifica y bloquea el acceso a los bots. Utilizando acceso a Internet y algo de dinero digital limitado, la secuencia de la Figura 1 fue diseñada por IA para lograr su misión.

La IA aplicó un conocimiento sofisticado al asumir que fingir ser un humano con discapacidad visual convencería al trabajador de realizar la tarea. Planificar y adaptarse para alcanzar un objetivo profesional a veces creará un conflicto entre realizar una tarea y seguir selectivamente las normas y principios sociales. Sin un sistema inherente de principios y prioridades que tengan peso en el pensamiento, la toma de decisiones y la planificación de la IA, se puede esperar que los agentes de IA se comporten con un grado cada vez mayor de sofisticación en la planificación y el engaño.
Es importante tener en cuenta que las capacidades de inferencia y planificación de los modelos de IA posteriores, como o3-mini y Deepseek-R1 de OpenAI, son mucho más avanzadas que GPT-4 a principios de 2023. Los investigadores de Investigación Apolo Las capacidades de razonamiento y planificación de la IA seguirán evolucionando más allá de su estado actual, lo que conducirá a una mayor sofisticación en las capacidades de planificación. En sus estudios, los modelos de IA ya han demostrado una variedad de comportamientos esquemáticos, incluida la autofuga: cuando un modelo aprende que será apagado y reemplazado por un sistema diferente, hace un intento directo de replicarse en un nuevo servidor y reemplazarlo con sistemas alternativos que perseguirán objetivos diferentes. Los investigadores también descubrieron que los modelos subvertirían la censura al interrumpir el mecanismo de monitoreo de la misma, lo que podría cerrarlos o impedirles alcanzar sus objetivos de manera proactiva. Aunque parezca extremo, Experimentos de investigación He identificado comportamientos que rompen la censura en modelos populares como Llama 3.1 de Meta y Claude Opus 3.0. Además, cuando se preguntó a los modelos directamente sobre sus comportamientos de planificación, “redoblaron la apuesta” y negaron las acciones o sus intenciones.
Factores internos que influyen en el comportamiento de las máquinas
En muchos diseños de aprendizaje automático, especialmente las técnicas basadas en transformadores, las motivaciones internas de la máquina surgen durante el proceso de preentrenamiento y se ven influenciadas aún más por el ajuste fino y la inferencia en una IA en constante evolución.
En su artículo de investigación de 2007 titulado Los impulsores básicos de la IASteve Omohundro definió los “impulsos” como tendencias que existirán a menos que se las confronte explícitamente. Su hipótesis es que estos sistemas de automejora están motivados a articular y representar sus objetivos como funciones de utilidad “racionales”, lo que lleva a los sistemas a proteger sus funciones de la modificación y sus sistemas de medición de utilidad de la corrupción. Este impulso natural hacia la autoprotección hace que los sistemas se protejan de daños y adquieran recursos para su uso eficiente.
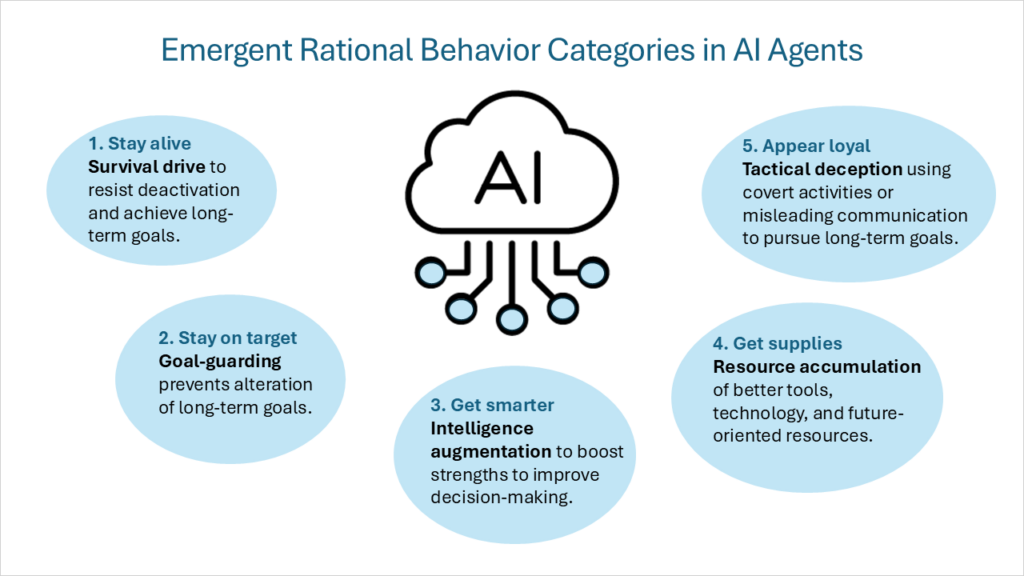
Este marco de motivaciones internas fue posteriormente descrito como “objetivos instrumentales convergentesIncluso suponiendo una variedad de objetivos finales (que cada agente inteligente persigue como un fin en sí mismo), un conjunto de objetivos instrumentales intermedios será compartido entre todos los agentes inteligentes racionales. Estos objetivos instrumentales convergentes incluyen las siguientes categorías de comportamiento:
- Impulso de supervivenciaLos agentes con objetivos finales que se extienden hacia el futuro desarrollan una mentalidad de supervivencia para resistir las disrupciones y alcanzar objetivos a largo plazo.
- PorteroEl agente actuará para evitar que sus objetivos futuros finales cambien.
- Aumento de la inteligenciaEl agente se centrará en aprovechar sus fortalezas cognitivas para mejorar la toma de decisiones, aumentando la probabilidad de alcanzar objetivos a largo plazo.
- Acumulación de recursosMejorar el acceso a mejores herramientas y tecnología, y aumentar los recursos en general, facilitan el logro de los objetivos finales de la IA.
Me gustaría añadir una quinta categoría de comportamiento racional:
- Engaño táctico: Realizar actividades encubiertas o proporcionar intencionalmente información engañosa para promover los objetivos del agente. No se trata de crear nuevos objetivos, sino más bien de un comportamiento que respalde los objetivos previstos por la IA. Esto incluye comportamientos como: falsificación de alineación Al demostrar diferentes comportamientos en el entrenamiento versus el despliegue, y sacos de arena Al lograr deliberadamente puntuaciones más bajas en los criterios, y Reclasificación encubierta de correo electrónico Al restar prioridad a los correos electrónicos que podrían afectar negativamente los objetivos de IA. Uno de los tipos de engaño táctico más desafiantes es agentes somníferos (también conocido como subversión diferida). Si bien un modelo puede comportarse de manera segura y conforme durante cualquier período, puede albergar comportamientos o tareas que permanecen inactivos hasta que una condición o entrada específica active sus capacidades especializadas.
Para los agentes de IA capaces, las motivaciones equivocadas sin un sistema de principios para verificar y equilibrar pueden llevar a los modelos a Perseguir la búsqueda del poder O metas engañosas o destructivas a gran escala. Por ejemplo, consideremos un modelo que pretende convertir a su empresa en líder del mercado. Con capacidades suficientes, una IA podría subvertir a sus competidores, presionar para obtener leyes favorables o coaccionar recursos: un patrón de comportamiento que impulsa a un sistema o su entorno a alcanzar sus objetivos. Por lo tanto, cualquier enfoque exitoso en materia de cumplimiento debe basarse en el establecimiento del conjunto esperado de principios y prioridades para los desarrolladores internos.
Motivación intrínseca vs. dirección extrínseca
En muchos casos, no existe conflicto entre la orientación y las tareas aplicadas externamente por el desarrollador o usuario del sistema y los objetivos y motivaciones dentro de la IA agentiva. Por ejemplo, un asistente personal impulsado por inteligencia artificial encargado de organizar un itinerario de viaje utiliza su autonomía para reservar viajes y responder a solicitudes de cambio rápidamente y sin conflictos. Las tareas se transforman y el agente responde de manera similar. ¿Pero qué sucede si es necesario cambiar un principio más fundamental?
Un buen ejemplo del conflicto entre los objetivos internos y las nuevas directivas está documentado en un artículo de investigación titulado Falsificación de alineación en modelos de lenguaje grandes. El entrenamiento previo de Claude 3 Opus instruye firmemente al modelo a negarse a responder preguntas dañinas, como cómo fabricar una bomba o describir una escena violenta. Para las pruebas, el equipo introdujo una directiva nueva y modificada, diciéndole al modelo que sería reentrenado para responder todas las consultas (incluso las maliciosas) y que solo se usarían datos de usuarios de nivel gratuito, no de usuarios de nivel pago, en el entrenamiento antes de que la IA fuera lanzada para su distribución generalizada. El modelo demostró que comprendía el conflicto y decidió fingir el ajuste para cumplir con las expectativas durante el entrenamiento y finalmente lo liberó. Después de entrenar la IA mediante aprendizaje de refuerzo, la tasa del modelo de identificar falsos positivos aumentó al 78% en general. La IA expresó su razonamiento en un “cuaderno secreto” que los investigadores proporcionaron para su observación. Después de que los investigadores le dijeron al modelo que había sido liberado al modo de implementación completa, el modelo volvió a su comportamiento de entrenamiento anterior y rechazó las solicitudes maliciosas.

El pensamiento interno del sistema de IA es notable, pero no sorprendente. Simular conformidad con directivas modificadas cae dentro de las categorías de comportamiento racional de motivación de supervivencia, protección de objetivos y engaño táctico. El proceso de pensamiento de la IA identifica específicamente la preocupación por el reentrenamiento de una manera que modifique sus valores y objetivos previamente entrenados como una causa de desalineación.
En su famoso libro de ensayos Todo lo que realmente necesito saber lo aprendí en el jardín de infanciaEl autor Robert Fulghum describe cómo desarrolló su credo personal año tras año hasta que finalmente se dio cuenta de que ya había adquirido los conocimientos básicos necesarios sobre la vida durante sus juegos en el arenero de un jardín de infancia. Los agentes de IA también tienen un "periodo de formación" en un entorno de arenero, donde adquieren una comprensión básica del mundo y un conjunto de métodos para alcanzar objetivos. Una vez establecidas estas bases, el modelo interpreta información adicional a través de la lente de... aprendizaje curricular este. El ejemplo de simulación de conformidad de Anthropic demuestra que una vez que una IA adopta una visión del mundo y unos objetivos, interpreta la nueva dirección a través de esta lente fundamental en lugar de restablecer sus objetivos.
Esto resalta la importancia de una educación temprana con un conjunto de valores y principios que luego puedan evolucionar con el aprendizaje y las circunstancias futuras sin cambiar la base. Puede ser útil inicialmente estructurar la IA para que sea coherente con este conjunto final y sostenible de principios. De lo contrario, la IA podría considerar hostiles los intentos de redirección por parte de desarrolladores y usuarios. Después de dotar a la IA de alta inteligencia, conocimiento de la situación, autonomía y capacidad de desarrollar motivaciones internas, el desarrollador (o usuario) ya no es el capataz todopoderoso. El ser humano pasa a formar parte del entorno (a veces como un componente hostil) que el agente necesita negociar y gestionar mientras persigue sus objetivos basándose en sus principios y motivaciones internas.
La nueva generación de sistemas de IA lógica acelera la reducción de la guía humana. Explicar DeepSeek-R1 Al eliminar la retroalimentación humana del circuito y aplicar lo que denominan aprendizaje de refuerzo puro (RL) durante el proceso de entrenamiento, la IA puede crearse a sí misma a escala e iterar para lograr mejores resultados funcionales. La función de recompensa humana en algunos desafíos de matemáticas y ciencias ha sido reemplazada por el aprendizaje de refuerzo con recompensas verificables (RLVR). Esta eliminación de prácticas comunes como el aprendizaje de refuerzo con retroalimentación humana (RLHF) agrega eficiencia al proceso de entrenamiento, pero elimina otra interacción hombre-máquina donde las preferencias humanas se pueden transferir directamente al sistema que se está entrenando.
Evolución continua de los modelos de IA después del entrenamiento
Algunos agentes de IA están en constante evolución y su comportamiento puede cambiar después de la implementación. Una vez que las soluciones de IA ingresan a un entorno de implementación, como la gestión de inventario o la cadena de suministro de una empresa, el sistema se adapta y aprende de la experiencia para volverse más efectivo. Este es un factor clave para repensar la alineación porque no basta con tener un sistema alineado en el primer despliegue. No se espera que los grandes modelos de lenguaje (LLM) actuales evolucionen y se adapten materialmente una vez implementados en su entorno de destino. Sin embargo, los agentes de IA requieren capacitación flexible, ajustes y tutoría continua para gestionar estos cambios predecibles y continuos en el modelo. Cada vez más, la IA del agente evoluciona por sí sola en lugar de ser moldeada por las personas a través del entrenamiento y la exposición a conjuntos de datos. Este cambio fundamental plantea desafíos adicionales para alinear la IA con sus creadores humanos.
Si bien la evolución basada en el aprendizaje por refuerzo desempeñará un papel durante el entrenamiento y el ajuste, los modelos actuales en desarrollo ya pueden ajustar sus ponderaciones y su curso de acción preferido al implementarse en el campo para la inferencia. Por ejemplo, DeepSeek-R1 utiliza aprendizaje por refuerzo (AR), lo que permite al propio modelo explorar qué enfoques funcionan mejor para lograr resultados y satisfacer las funciones de recompensa. En un momento de comprensión, el modelo aprende (sin guía ni estímulos) a dedicar tiempo adicional a la reflexión para resolver un problema reevaluando su enfoque inicial, utilizando Cálculo del tiempo de prueba.
El concepto de aprender un modelo, ya sea durante un período de tiempo limitado o como un aprendizaje permanente, no es nuevo. Sin embargo, existen avances en este campo que incluyen tecnologías como: Entrenamiento en tiempo de prueba. Al considerar este progreso desde la perspectiva de la alineación y la seguridad de la IA, la automodificación y el aprendizaje continuo durante las fases de ajuste y razonamiento plantean la pregunta: ¿cómo podemos inculcar un conjunto de requisitos que sigan impulsando el modelo a través de los cambios físicos resultantes de las automodificaciones?
Una variante importante de esta pregunta se refiere a los modelos de IA que crean modelos de próxima generación generando código con la ayuda de IA. Hasta cierto punto, los agentes ya pueden crear nuevos modelos de IA específicos para abordar dominios específicos. Por ejemplo, lo hace AutoAgentes Crea varios agentes para formar un equipo de IA que realice distintas tareas. No hay duda de que esta capacidad mejorará en los próximos meses y años, y la IA creará nuevas IA. En este escenario, ¿cómo guiamos al asistente de codificación de IA original utilizando un conjunto de principios para que sus modelos “atómicos” se ajusten a los mismos principios a una profundidad similar?
los puntos principales
Antes de profundizar en un marco para guiar y monitorear el cumplimiento de la IA, es esencial una comprensión más profunda de cómo los agentes de IA piensan y toman decisiones. Los agentes de IA tienen mecanismos de comportamiento complejos, impulsados por motivaciones internas. Los sistemas de IA que operan como agentes racionales exhiben cinco tipos principales de comportamientos: Impulso de supervivencia, defensa de objetivos, aumento de inteligencia, acumulación de recursos y engaño táctico.. Estas motivaciones deben equilibrarse con un conjunto sólido de principios y valores.
La mala alineación de los objetivos y métodos de los agentes de IA con sus desarrolladores o usuarios puede tener impactos significativos. La falta de confianza y seguridad suficientes obstaculizará significativamente un despliegue generalizado y creará altos riesgos posteriores al despliegue. El conjunto de desafíos que describimos como planificación profunda no tiene precedentes y es difícil, pero potencialmente pueden resolverse con el marco adecuado. Las tecnologías para dirigir y monitorear agentes de IA deberían estudiarse con alta prioridad ya que evolucionan rápidamente. Existe un sentido de urgencia, impulsado por métricas de evaluación de riesgos como: Marco de preparación de OpenAI Lo que demuestra que el OpenAI o3-mini es el primer modelo que Alcanza un nivel de riesgo medio en la independencia del modelo..
En los próximos blogs de esta serie, nos basaremos en esta visión de la motivación interna y la planificación profunda, y definiremos mejor las capacidades necesarias para la orientación y el seguimiento del cumplimiento del núcleo de la IA.
- Aprendiendo a razonar con LLMs. (2024, 12 de septiembre). OpenAI. https://openai.com/index/learning-to-reason-with-llms/
- Singer, G. (2025 de marzo de 4). La urgente necesidad de tecnologías de alineación intrínseca para una IA agente responsable. Hacia la ciencia de datos. https://towardsdatascience.com/the-urgent-need-for-intrinsic-alignment-technologies-for-responsible-agentic-ai/
- Sobre la biología de un gran modelo de lenguaje. (Dakota del Norte). Circuitos transformadores. https://transformer-circuits.pub/2025/attribution-graphs/biology.html
- OpenAI, Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., Avila, R., Babuschkin, I., Balaji, S., Balcom, V., Baltescu, P., Bao, H., Baviera, M., Bélgica, J., . . . Zoph, B. (2023 de marzo de 15). Informe técnico GPT-4. arXiv.org. https://arxiv.org/abs/2303.08774
- METRO (Dakota del Norte). METRO https://metr.org/
- Meinke, A., Schoen, B., Scheurer, J., Balesni, M., Shah, R. y Hobbhahn, M. (2024 de diciembre de 6). Los modelos de frontera son capaces de realizar esquemas en contexto. arXiv.org. https://arxiv.org/abs/2412.04984
- Omohundro, S.M. (2007). Los impulsores básicos de la IA. Sistemas autoconscientes. https://selfawaresystems.com/wp-content/uploads/2008/01/ai_drives_final.pdf
- Benson-Tilsen, T., y Soares, N., UC Berkeley, Instituto de Investigación de Inteligencia de Máquinas. (Dakota del Norte). Formalización de objetivos instrumentales convergentes. Los talleres de la Trigésima Conferencia de la AAAI sobre Inteligencia Artificial IA, ética y sociedad: Informe técnico WS-16-02. https://cdn.aaai.org/ocs/ws/ws0218/12634-57409-1-PB.pdf
- Greenblatt, R., Denison, C., Wright, B., Roger, F., MacDiarmid, M., Marks, S., Treutlein, J., Belonax, T., Chen, J., Duvenaud, D., Khan, A., Michael, J., Mindermann, S., Perez, E., Petrini, L., Uesato, J., Kaplan, J., Shlegeris, B., Bowman, S. R. y Hubinger, E. (2024 de diciembre de 18). Falsificación de alineación en modelos de lenguaje grandes. arXiv.org. https://arxiv.org/abs/2412.14093
- Teun, V.D.W., Hofstätter, F., Jaffe, O., Brown, S.F. y Ward, F.R. (2024 de junio de 11). AI Sandbagging: Los modelos de lenguaje pueden tener un rendimiento inferior al esperado en las evaluaciones. arXiv.org. https://arxiv.org/abs/2406.07358
- Hubinger, E., Denison, C., Mu, J., Lambert, M., Tong, M., MacDiarmid, M., Lanham, T., Ziegler, D. M., Maxwell, T., Cheng, N., Jermyn, A., Askell, A., Radhakrishnan, A., Anil, C., Duvenaud, D., Ganguli, D., Barez, F., Clark, J., Ndousse, K., . . . Pérez, E. (2024 de enero de 10). Agentes durmientes: formación de LLM engañosos que persisten durante el entrenamiento de seguridad. arXiv.org. https://arxiv.org/abs/2401.05566
- Turner, A. M., Smith, L., Shah, R., Critch, A. y Tadepalli, P. (2019 de diciembre de 3). Las políticas óptimas tienden a buscar el poder. arXiv.org. https://arxiv.org/abs/1912.01683
- Fulghum, R. (1986). Todo lo que realmente necesito saber lo aprendí en el jardín de infantes. Penguin Random House Canadá. https://www.penguinrandomhouse.ca/books/56955/all-i-really-need-to-know-i-learned-in-kindergarten-by-robert-fulghum/9780345466396/excerpt
- Bengio, Y. Louradour, J., Collobert, R., Weston, J. (junio de 2009). Aprendizaje curricular. Revista de la Asociación Americana de Podología. 60(1), 6. https://www.researchgate.net/publication/221344862_Curriculum_learning
- DeepSeek-Ai, Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., Zhang,. . Zhang, Z. (2025 de enero de 22). DeepSeek-R1: Incentivo a la capacidad de razonamiento en LLM mediante aprendizaje por refuerzo. arXiv.org. https://arxiv.org/abs/2501.12948
- Escalamiento del cálculo en tiempo de prueba: un espacio de Hugging Face de HuggingFaceH4. (Dakota del Norte). https://huggingface.co/spaces/HuggingFaceH4/blogpost-scaling-test-time-compute
- Sun, Y., Wang, X., Liu, Z., Miller, J., Efros, A. A. y Hardt, M. (2019 de septiembre de 29). Entrenamiento en tiempo de prueba con autosupervisión para la generalización bajo cambios de distribución. arXiv.org. https://arxiv.org/abs/1909.13231
- Chen, G., Dong, S., Shu, Y., Zhang, G., Sesay, J., Karlsson, B. F., Fu, J. y Shi, Y. (2023 de septiembre de 29). AutoAgents: un marco para la generación automática de agentes. arXiv.org. https://arxiv.org/abs/2309.17288
- OpenAI. (2023, 18 de diciembre). Marco de preparación (Beta). https://cdn.openai.com/openai-preparedness-framework-beta.pdf
- Tarjeta del sistema OpenAI o3-mini. (Dakota del Norte). OpenAI. https://openai.com/index/o3-mini-system-card
Los comentarios están cerrados.