

¿Cómo puede asegurarse de que sus soluciones de IA funcionen como espera?
Una breve introducción a las evaluaciones de IA
La IA generativa (GenAI) está evolucionando rápidamente y ya no se trata solo de chatbots divertidos o generación de imágenes impresionantes. 2025 es el año en que nos centraremos en convertir el entusiasmo en torno a la IA en valor real. Las empresas de todo el mundo buscan formas de integrar y aprovechar GenAI en sus productos y operaciones para brindar un mejor servicio a los usuarios, mejorar la eficiencia, mantener la competitividad e impulsar el crecimiento. Con API y modelos previamente entrenados de proveedores líderes, integrar GenAI parece más fácil que nunca. Pero aquí está el quid de la cuestión: El hecho de que la integración sea fácil no significa que las soluciones de IA funcionarán como se espera una vez implementadas.

Los modelos predictivos no son realmente nuevos: como humanos, hemos estado prediciendo cosas durante años, comenzando oficialmente con estadísticas. Sin embargo, GenAI está revolucionando el campo de la previsión por muchas razones.:
- No es necesario entrenar su propio modelo ni ser un científico de datos para crear soluciones de IA.
- La IA ahora es fácil de usar a través de interfaces de chat y fácil de integrar a través de API.
- Liberando muchas cosas que antes no era posible hacer o eran realmente difíciles de hacer.
Todas estas cosas hacen GenAI es muy emocionante, pero también arriesgado.. A diferencia del software tradicional, o incluso del aprendizaje automático clásico, GenAI ofrece un nuevo nivel de imprevisibilidad. No estás implementando una lógica determinista, estás utilizando un modelo entrenado con cantidades masivas de datos, esperando que responda según sea necesario. Entonces, ¿cómo sabemos si un sistema de IA está haciendo lo que pretendemos que haga? ¿Cómo sabemos si está listo para funcionar? La respuesta son las evaluaciones, un concepto que exploraremos en este post:
- Por qué los sistemas Genai no se pueden probar de la misma manera que el software tradicional o incluso el aprendizaje automático clásico (ML)
- Por qué las calificaciones son esenciales para comprender la calidad de su sistema de IA y no opcionales (a menos que le gusten las sorpresas)
- Diferentes tipos de evaluaciones y técnicas para aplicarlas en la práctica
Ya sea que sea un gerente de producto, un ingeniero o cualquier persona que trabaje o esté interesado en IA, espero que esta publicación lo ayude a comprender cómo pensar críticamente sobre la calidad de los sistemas de IA (y por qué las evaluaciones son esenciales para lograr esa calidad).
La IA generativa no se puede probar como el software tradicional, ni siquiera como el aprendizaje automático clásico.
En el desarrollo de software tradicionalLos sistemas siguen una lógica determinista: Si sucede X, entonces sucederá Y. - siempre. A menos que algo salga mal con tu plataforma o introduzcas un error en tu código… es por eso que agregamos pruebas, monitoreo y alertas. Las pruebas unitarias se utilizan para validar pequeños bloques de código, las pruebas de integración para garantizar que los componentes funcionen bien juntos y la monitorización para detectar si algo está roto en la producción. Las pruebas de software tradicionales son como comprobar el funcionamiento de una calculadora. Ingresas 2 + 2 y esperas 4. Claro e inevitable, es verdadero o falso.
Sin embargo, el aprendizaje automático y la inteligencia artificial introducen indeterminismo y probabilidad. En lugar de especificar explícitamente el comportamiento a través de reglas, entrenamos modelos para aprender patrones a partir de los datos. En IA, si sucede X, el resultado ya no es un Y codificado, sino una predicción con cierto grado de probabilidad, basada en lo que el modelo aprendió durante el entrenamiento.. Esto puede ser muy poderoso, pero también introduce incertidumbre: entradas idénticas pueden tener salidas diferentes a lo largo del tiempo, salidas plausibles pueden ser en realidad incorrectas y puede surgir un comportamiento inesperado en escenarios excepcionales...
Esto hace que los métodos de prueba tradicionales sean insuficientes y, a veces, incluso inviables. El ejemplo de la calculadora se acerca a intentar evaluar el desempeño de un estudiante en un examen abierto. Para cada pregunta y muchas formas posibles de responderla, ¿es correcta la respuesta dada? ¿Está por encima del nivel de conocimientos que debería tener el estudiante? ¿El estudiante lo inventó todo pero suena muy convincente? Al igual que las respuestas de un examen, Los sistemas de IA se pueden evaluar, pero necesitan una forma más general y flexible de adaptarse a diferentes entradas, contextos y casos de uso. (o tipos de pruebas).
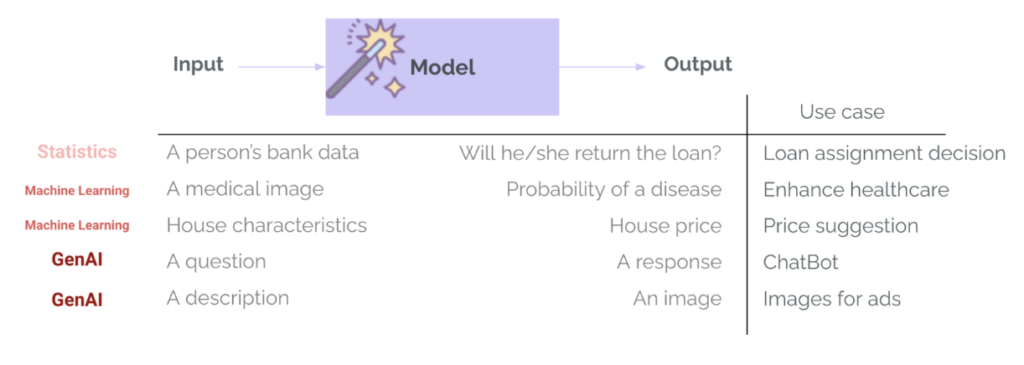
في aprendizaje automático Tradicionalmente (ML), las evaluaciones ya son una parte establecida del ciclo de vida del proyecto.. Entrenar un modelo en una tarea específica, como la aprobación de un préstamo o la detección de una enfermedad, siempre incluye un paso de evaluación, en el que se utilizan métricas como la precisión, la recuperación, el RMSE, el MAE, etc. Esto se utiliza para medir el rendimiento del modelo, comparar diferentes opciones de modelo y determinar si el modelo es lo suficientemente bueno como para pasar a la implementación. En GenAI, esto generalmente cambia: los equipos usan modelos que ya han sido entrenados y que ya han pasado evaluaciones de propósito general internamente por parte del proveedor del modelo y en puntos de referencia públicos. Estos modelos son muy buenos para tareas generales (como responder preguntas o redactar correos electrónicos) y existe el riesgo de confiar demasiado en ellos para nuestro caso de uso específico. Sin embargo, es importante preguntar: “¿Es esta increíble plantilla lo suficientemente buena para mi caso de uso?“Aquí es donde entra la evaluación”. – Evaluar si las predicciones o generaciones son buenas para un caso de uso, contexto, entradas y usuarios específicos.

Hay otra diferencia importante entre ML y GenAI: la variedad y complejidad de los resultados del modelo. Ya no devolvemos categorías y probabilidades (como la probabilidad de que un cliente devuelva un préstamo), ni números (como el precio esperado de una casa en función de sus características). Los sistemas GenAI pueden devolver muchos tipos de salida, con diferentes duraciones, tonos, contenidos y formatos. Asimismo, estos modelos ya no requieren entradas altamente estructuradas y específicas, sino que suelen aceptar casi cualquier tipo de entrada: texto, imágenes o incluso audio o vídeo. Por eso la evaluación se vuelve mucho más difícil.
Por qué las evaluaciones son necesarias, no opcionales (a menos que prefieras sorpresas desagradables)
Las evaluaciones le ayudan a medir si su sistema de IA realmente funciona como usted esperaba. Tú lo quieres, si el sistema está listo para funcionar y, de ser así, si continúa funcionando como se espera. A continuación se presenta un análisis de por qué son importantes las evaluaciones:
- Evaluación de calidad: Las evaluaciones proporcionan una forma estructurada de comprender la calidad de sus predicciones o resultados de IA y cómo se integrarán en el sistema general y el caso de uso. ¿Son precisas las respuestas? ¿Útil? ¿Cohesivo? ¿Relacionado?
- Cuantificar errores: Las calificaciones ayudan a determinar el porcentaje, los tipos y la magnitud de los errores. ¿Con qué frecuencia ocurren errores? ¿Qué tipos de errores ocurren con mayor frecuencia (por ejemplo, falsos positivos, alucinaciones, errores de formato)?
- Mitigación de riesgos: Le ayuda a detectar y prevenir comportamientos dañinos o sesgados antes de que lleguen a los usuarios, protegiendo así a su empresa de riesgos de reputación, problemas éticos y posibles problemas regulatorios.
La IA generativa, con relaciones de entrada-salida libres y generación de texto largo, hace que las evaluaciones sean más relevantes y complejas. Cuando las cosas van mal, pueden ir muy mal. Todos hemos visto los titulares sobre chatbots que ofrecen consejos peligrosos, modelos que generan contenido sesgado y herramientas de IA que alucinan con datos falsos.
"La IA nunca será perfecta, pero al usar evaluaciones puedes reducir el riesgo de pasar vergüenza, lo que podría costarte dinero, credibilidad o un momento viral en Twitter."
¿Cómo se define una estrategia de evaluación de IA?

Entonces, ¿cómo determinamos nuestras calificaciones de IA? No existe un método de evaluación que se adapte a todos. Las evaluaciones dependen del caso de uso específico y deben alinearse con los objetivos específicos de su aplicación de IA. Por ejemplo, si estás creando un motor de búsqueda, es posible que te interese la relevancia de los resultados. Si se trata de un chatbot, es posible que le interese la utilidad y la seguridad. Si es información clasificada, probablemente le importará la exactitud y la precisión. Para los sistemas que implican múltiples pasos (como un sistema de IA que realiza una búsqueda, prioriza los resultados y luego genera una respuesta), a menudo es necesario evaluar cada paso. La idea aquí es medir si cada paso ayuda a lograr la métrica de éxito general (y a partir de esto, comprender dónde centrar las iteraciones y las mejoras).
Las áreas de evaluación comunes incluyen:
- Corrección y alucinaciones: ¿Son los resultados realistas y precisos? ¿El sistema genera información incorrecta o alucinaciones?
- Pertinencia: ¿El contenido es consistente con la consulta del usuario o el contexto proporcionado?
- seguridad, sesgo y toxicidad
- Formato: ¿La salida está en el formato esperado (por ejemplo, JSON, llamada de función válida)?
- Seguridad, sesgo y toxicidad: ¿El sistema genera contenido dañino, sesgado o tóxico?
Métricas específicas de la tarea. Por ejemplo, en tareas de clasificación se utilizan métricas como exactitud y precisión, en tareas de resumen ROUGE o BLEU, y en tareas de generación de código regex y verificación de ejecución sin errores.
¿Cómo se calculan realmente las evaluaciones?
Una vez que haya determinado lo que desea medir, el siguiente paso es diseñar sus casos de prueba. Este será un conjunto de ejemplos (cuanto más mejor, pero siempre equilibrando valor y costes) donde tienes:
- Ejemplo de entrada:Una introducción realista de su sistema una vez que entra en producción.
- Resultados esperados (Si corresponde): Hecho clave o ejemplo de resultados deseados.
- Método de evaluación: Mecanismo de registro para evaluar el resultado.
- Resultado o éxito/fracaso:Una métrica calculada que evalúa su caso de prueba.
Dependiendo de sus necesidades, tiempo y presupuesto, existen varias técnicas que puede utilizar como métodos de evaluación:
- Herramientas de registro estadístico como: BLEU, ROUGE y METEOR, o medida de similitud de coseno entre incrustaciones: útil para comparar el texto generado con la salida de referencia.
- Métricas tradicionales de aprendizaje automático como Precisión, recuperación y AUC: ideal para clasificación con datos etiquetados.
- Modelo de Lenguaje Grande como Juez (LLM como Juez) Utilice un modelo de lenguaje grande para evaluar el resultado (por ejemplo, “¿Es esta respuesta correcta y útil?“). Especialmente útil cuando no se dispone de datos no clasificados o cuando se evalúa un constructo abierto.
Evaluaciones basadas en códigos Utilice expresiones regulares, reglas lógicas o implementación de casos de prueba para validar formatos.
La línea de fondo
Pongamos todo junto con un ejemplo concreto. Imagina que estás construyendo un sistema de análisis de sentimientos para ayudar a tu equipo de atención al cliente a priorizar los correos electrónicos entrantes.
El objetivo es garantizar que los mensajes más urgentes o negativos obtengan respuestas más rápidas, lo que reduce la frustración, mejora la satisfacción y disminuye la pérdida de clientes. Este es un caso de uso relativamente simple, pero incluso en un sistema como este, con resultados limitados, la calidad importa: las malas predicciones podrían provocar que los correos electrónicos se prioricen aleatoriamente, lo que significa que su equipo está perdiendo tiempo con un sistema que cuesta dinero.
Entonces, ¿cómo sabe que su solución está funcionando tan bien como desea? Estás evaluando. A continuación se muestran algunos ejemplos de cosas que podrían ser relevantes para evaluar en este caso de uso específico:
- Validación de formato: ¿Los resultados de una llamada a un modelo de lenguaje grande (LLM) para predecir el sentimiento del correo electrónico se devuelven en el formato JSON esperado? Esto se puede evaluar mediante comprobaciones basadas en código: expresiones regulares, validación de esquema, etc.
- Precisión de la clasificación de sentimientos: ¿El sistema clasifica correctamente el sentimiento en una variedad de textos (cortos, largos y multilingües)? Esto se puede evaluar utilizando datos etiquetados mediante métricas de aprendizaje automático tradicionales (métricas ML) o, si las etiquetas no están disponibles, utilizando un modelo de lenguaje grande (LLM) como juez.
Una vez que la solución esté activa, también querrá incluir las métricas más estrechamente relacionadas con el impacto final de su solución.:
- Eficacia de la priorización: ¿Los agentes de soporte realmente son dirigidos a los correos electrónicos más importantes? ¿La priorización se alinea con el impacto empresarial deseado?
- Impacto comercial final: Con el tiempo, ¿este sistema reduce los tiempos de respuesta, reduce la pérdida de clientes y mejora los índices de satisfacción?
Las evaluaciones son esenciales para garantizar que los sistemas de IA sean útiles, seguros, valiosos y estén listos para los usuarios de producción. Entonces, ya sea que trabajes con un clasificador simple o un chatbot abierto, tómate el tiempo para definir qué significa "suficientemente bueno" (calidad mínima viable) y crea evaluaciones en torno a ello para medirlo.
Referencias
[ 1 ] Su producto de IA necesita evaluacionesHamel Husain
[ 2 ] Métricas de evaluación de LLM: La guía definitiva de evaluación de LLM, Confident AI
[ 3 ] Evaluación de agentes de IA, deeplearning.ai + Arize
Los comentarios están cerrados.