

Probé la nueva función de generación de imágenes nativas de Gemini y es absolutamente increíble.
Resumen:
- Google ha lanzado la generación y edición de imágenes nativas utilizando la nueva versión beta de Flash Gemini 2.0.
- La función está disponible ahora de forma gratuita en AI Studio y permite generar y editar una serie de imágenes coordinadas mediante comandos de texto simples.
- Puede eliminar y agregar elementos, insertar texto, colorear imágenes, crear una historia visual y mucho más.
Hemos estado escuchando el término "multimodal nativo" en IA durante más de un año, pero las empresas han tardado en liberar todo el potencial multimodal de sus modelos de IA hasta ahora. Google finalmente lanzó su último prototipo, el “Gemini 2.0 Flash Experimental”, con… Capacidad de generar y editar imágenes originales.Oh.
Ahora, te estarás preguntando, ¿cuál es la importancia de la generación de imágenes? La generación de imágenes con IA está disponible desde hace algún tiempo con los principales chatbots de IA como ChatGPT. Bueno, cuando generamos imágenes de IA en ChatGPT o Gemini, se dirige a un modelo especializado basado en difusión como Dall-E 3 o Imagen 3. Estos modelos se entrenan en imágenes y están diseñados solo para generar imágenes; Es una extensión del modelo principal de IA, no parte de él.
Sin embargo, los modelos de visión lingüística como Gemini Nativamente multimedia, lo que significa que puede comprender, generar y modificar tanto texto como imágenes de forma inherente. Hasta el momento, ninguna empresa tecnológica ha puesto esta capacidad a disposición de los usuarios. OpenAI demostró su función de generación de imágenes nativa con GPT-4o en 2024, pero nuevamente, nunca se lanzó.
 Con la función de generación de imágenes originales, obtendrás: Mejor coordinación Donde los modelos multimodales se entrenan en un conjunto enorme de datos de diferentes medios. Como resultado, estos modelos tienen una mejor comprensión de los conceptos y demuestran un conocimiento más amplio del mundo.
Con la función de generación de imágenes originales, obtendrás: Mejor coordinación Donde los modelos multimodales se entrenan en un conjunto enorme de datos de diferentes medios. Como resultado, estos modelos tienen una mejor comprensión de los conceptos y demuestran un conocimiento más amplio del mundo.
Además de generar imágenes, puedes editarlas fácilmente con comandos de texto sencillos. Por ejemplo, puedes subir una imagen y pedirle al modelo que añada gafas de sol, inserte texto en negrita, elimine objetos, etc. A diferencia de los modelos de difusión, que regeneran la imagen completa con cada nuevo comando, los modelos multimedia nativos mantienen la coherencia en múltiples ediciones.
Cree imágenes usando la demostración Flash de Gemini 2.0
Actualmente, la función de creación de imágenes originales no está disponible para los usuarios públicos. La demostración Flash de Gemini 2.0 con generación de imágenes nativas solo está disponible en la plataforma AI Studio de Google (Visita) de forma gratuita.
Después de obtener una vista previa del modelo en AI Studio, se lanzará en Gemini para que todos puedan usarlo en un futuro cercano. Sin embargo, probé el nuevo modelo Gemini con la función de creación de imágenes y fue una experiencia muy emocionante.
Primero, comencé con una guía visual para mostrar la consistencia de la capacidad de generación de imágenes de Gemini. Le pedí a Gemini que creara una guía visual sobre cómo hacer una tortilla, creando una foto para cada paso del proceso.
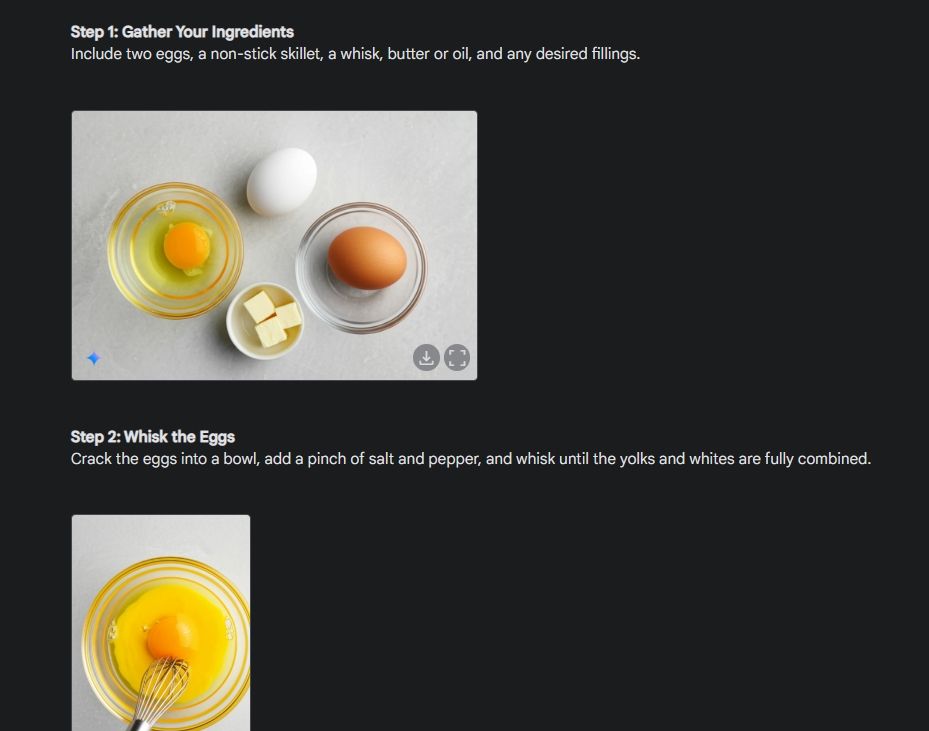
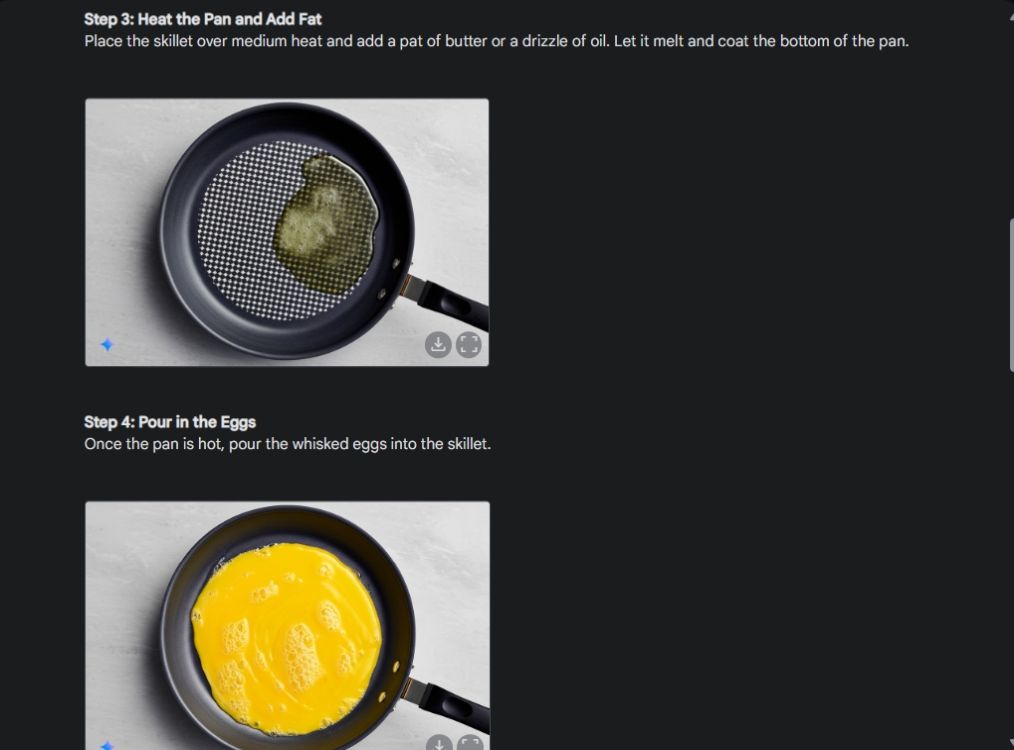

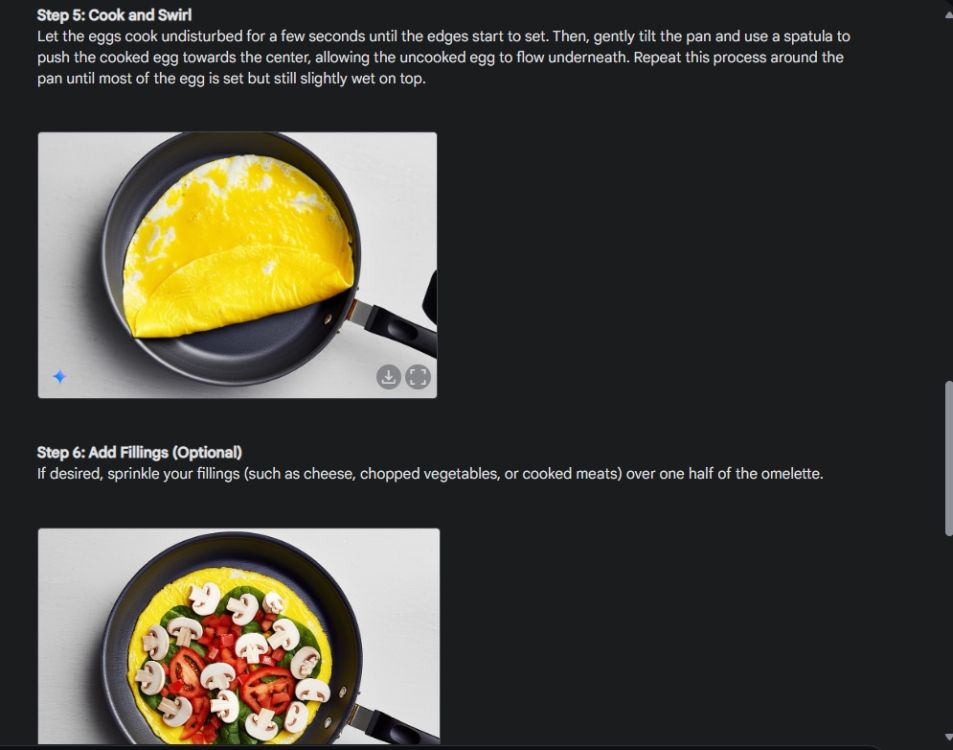
Como puedes ver, los resultados son muy consistentes en todas las imágenes sin ningún error. Incluso el cuenco es el mismo que en la segunda foto. Por último, puedes descargar imágenes en resolución 1024 x 680. De esta manera, puedes crear una guía visual para cualquier cosa que desees.
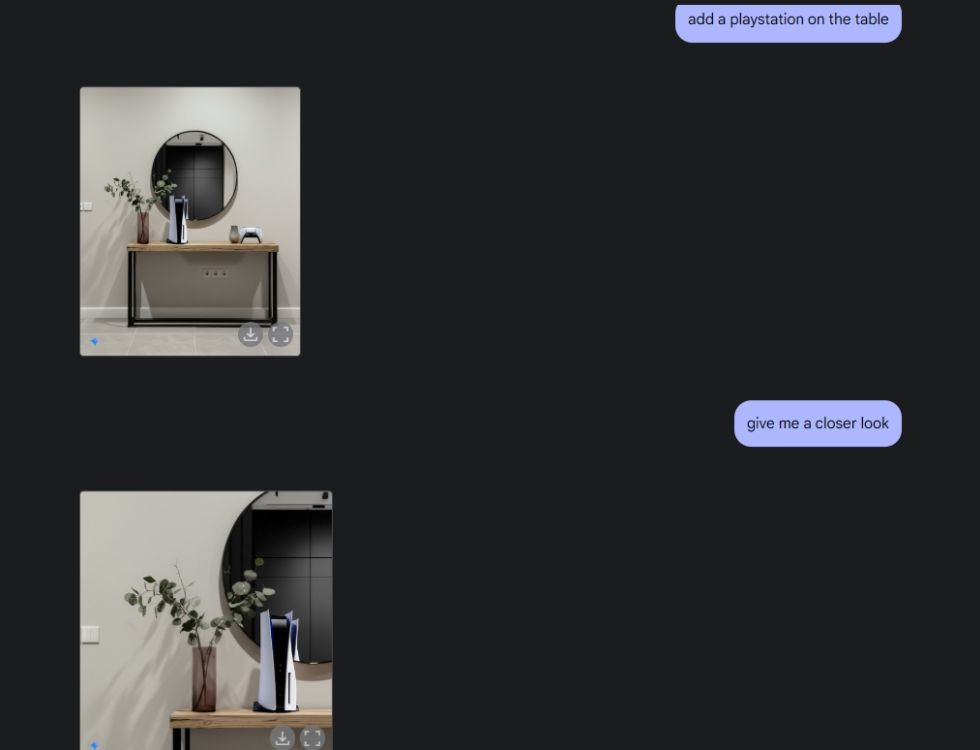
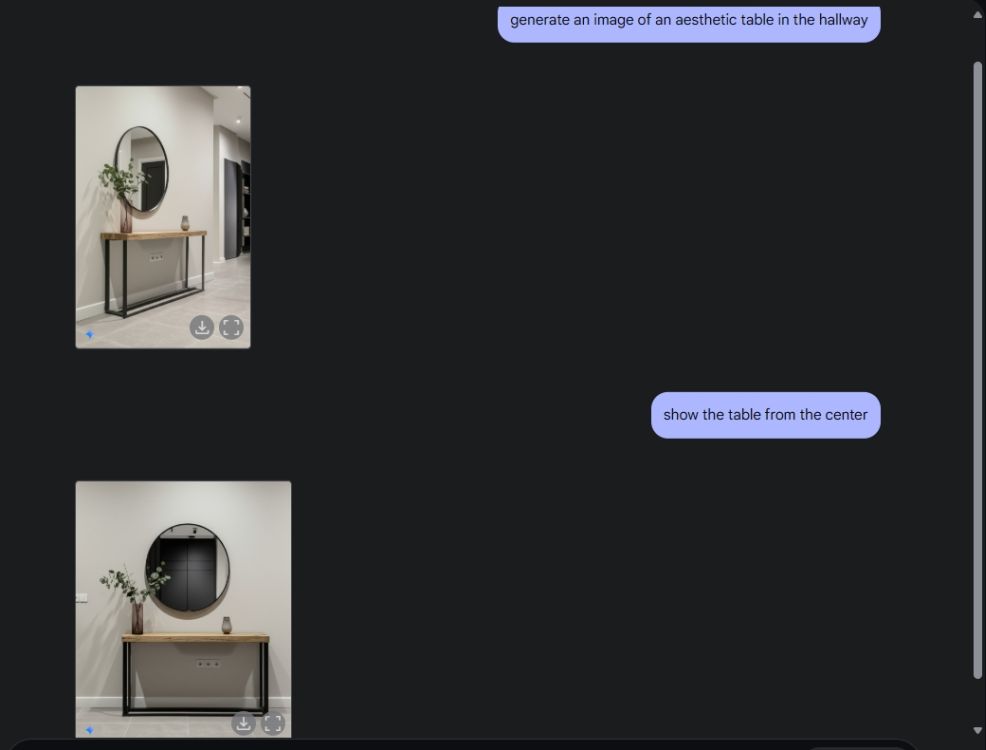
A continuación, le pedí a Gemini que creara una imagen de mesa estética y luego le pedí que viera la mesa desde el ángulo central de la cámara. Hizo un trabajo perfecto. A continuación, le pedí a Gemini que agregara una PlayStation a la mesa y la observara más de cerca. Una vez más, Géminis acertó. Como puedes ver a continuación, el modelo de IA también incluyó un reflejo de la PS5 en el espejo detrás de ella.
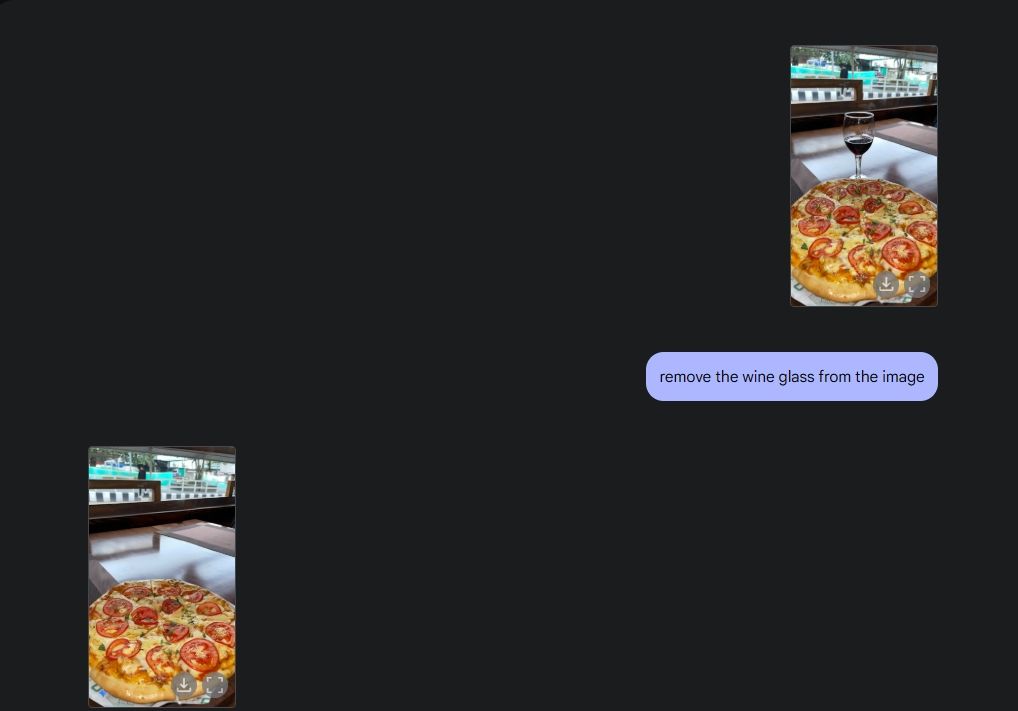
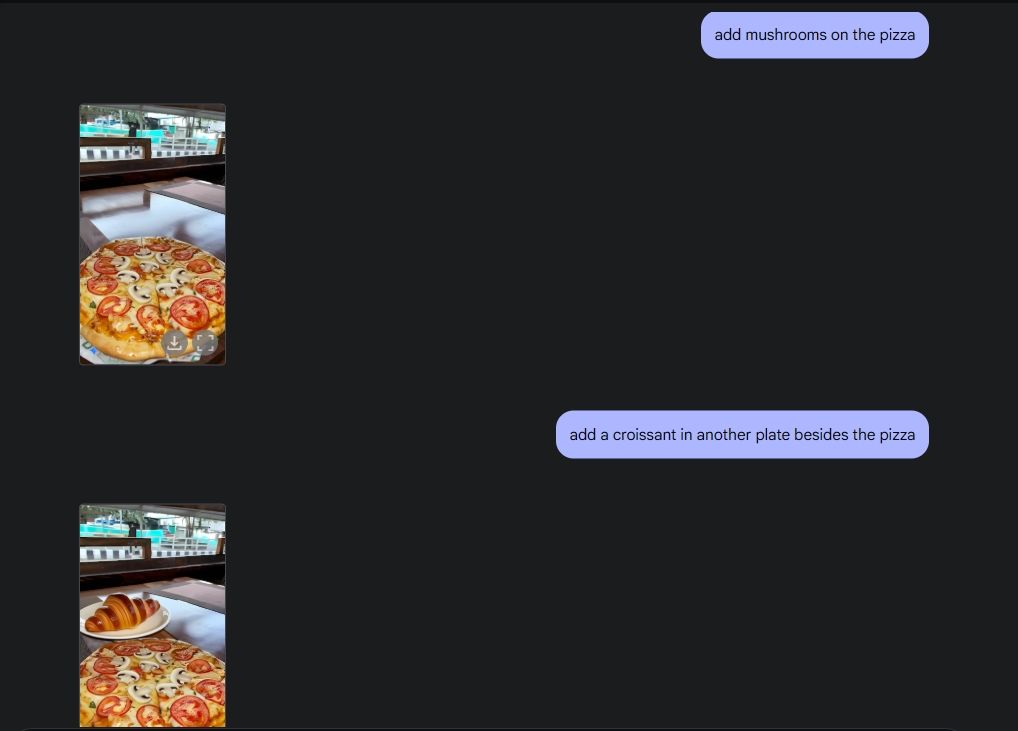
Para demostrar la edición original de la foto, subí una foto de mi galería y le pedí a Gemini 2.0 que retirara la copa de vino de la mesa. Luego le pedí a Géminis que añadiera champiñones a la pizza y lo hizo muy bien. Luego le pedí a Gemini que añadiera un croissant y ahí lo tienes, edición de fotos con IA con todas sus funciones, gracias a las capacidades multimedia de Gemini.
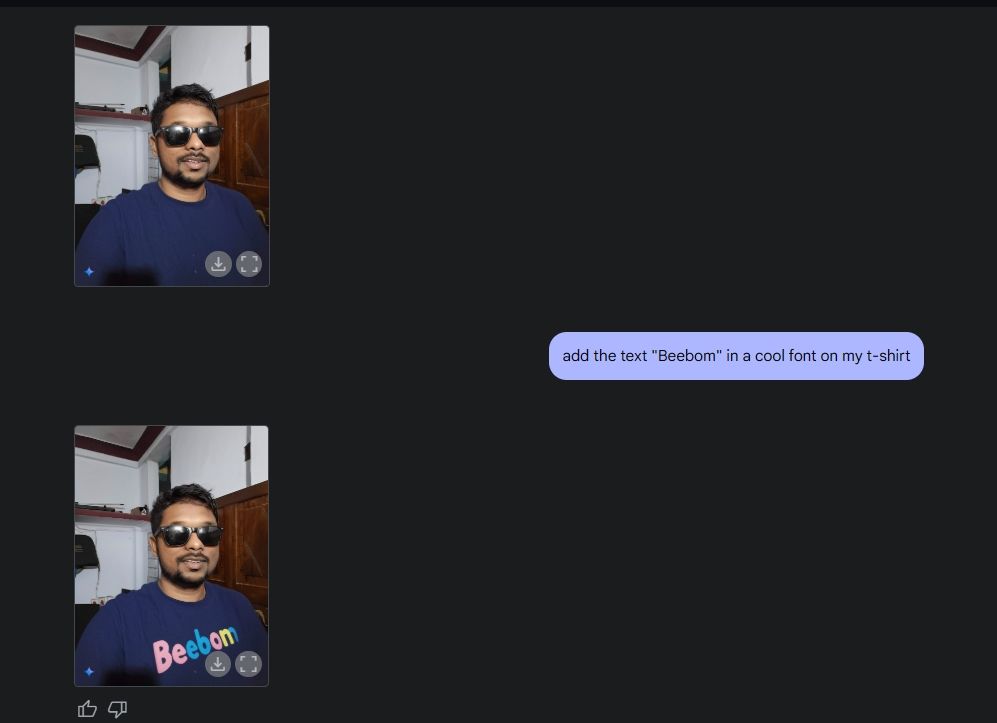
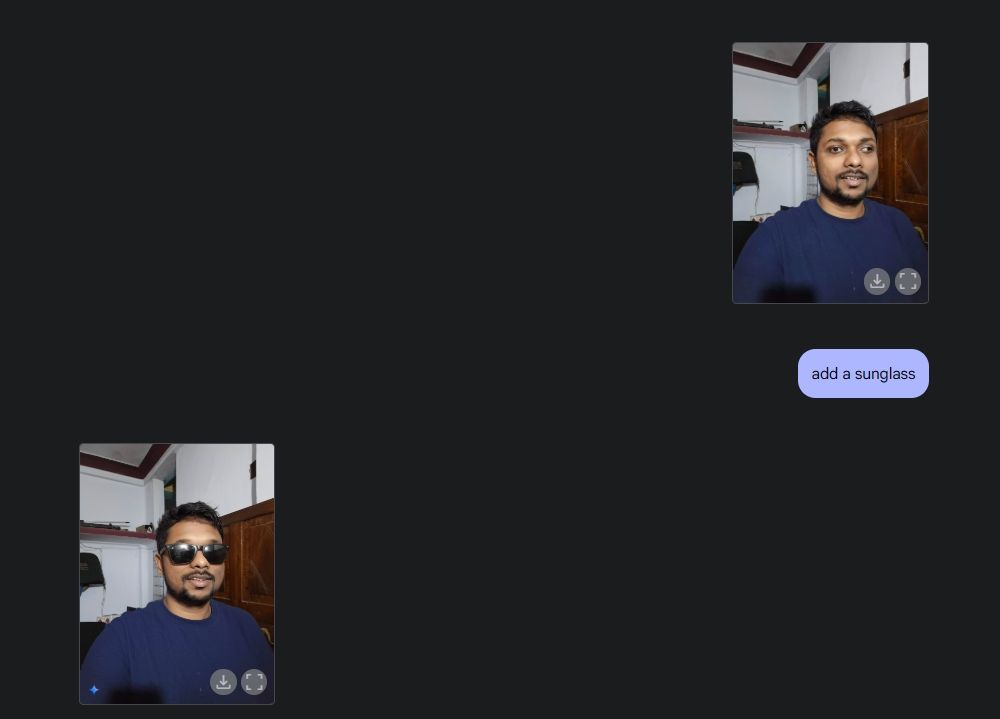
Luego, subí una foto mía, le pedí a Gemini que agregara gafas de sol y luego agregué el texto “Beebom” a mi camiseta. Ambos fueron ejecutados muy bien.
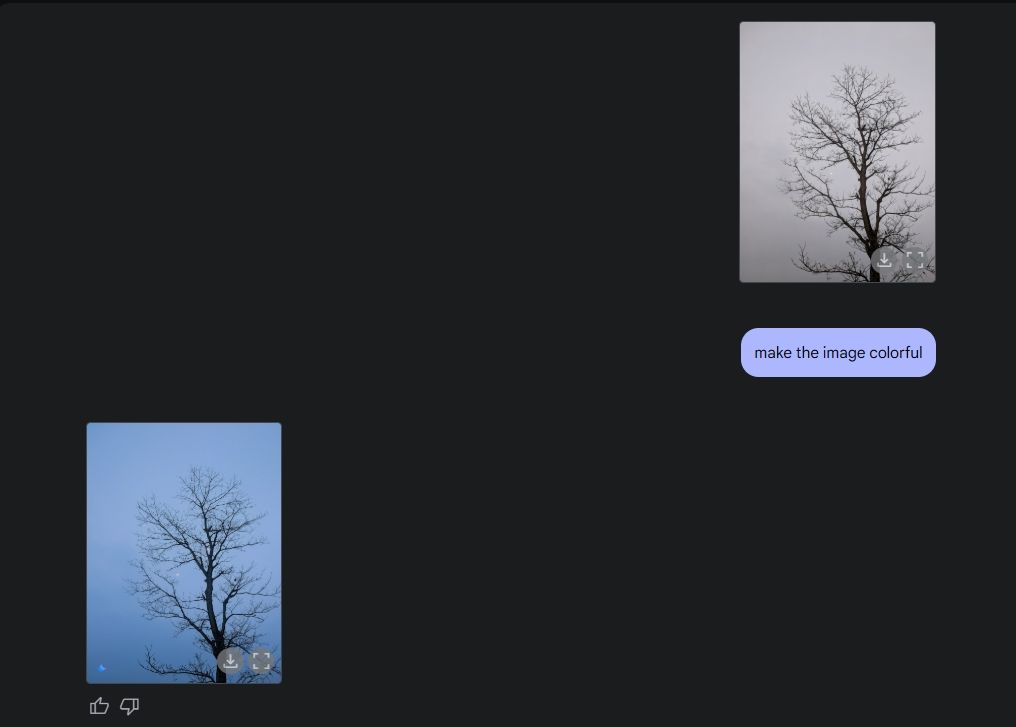
Finalmente le pedí a Géminis que coloreara un dibujo y también lo hizo muy bien. Quiero decir, la imagen es más bonita que antes, sin ningún error extraño, distorsiones o falta de alguna parte de la imagen.
Hay muchos casos de uso que puedes experimentar con las nuevas capacidades multimedia de Gemini. Google ha hecho un gran trabajo con la creación y edición de imágenes nativas, y planeo usarlo más a fondo en las próximas semanas para probar sus límites.
Después de lanzar Veo 2 para la creación de videos e Imagen 3 para la creación de imágenes especializadas, Google parece haber superado a OpenAI en muchas áreas; No sólo en el campo de la generación de texto mediante IA. Entonces, será interesante ver qué hace OpenAI para recuperar el liderazgo con ChatGPT.
Los comentarios están cerrados.