

Calificación de audiencia: 27 modelos de IA, ChatGPT en el octavo lugar: estos son los modelos que lo superaron
Aunque el mundo inteligencia artificial (IA) Si bien a menudo puede parecer un área turbulenta, hay una sorprendente cantidad de análisis, evaluación comparativa y pruebas que se realizan detrás de escena, no solo por parte de las propias empresas, sino también por grupos creados para determinar sus propias clasificaciones.

Estos grupos prueban todo, desde la capacidad de un chatbot para completar pruebas de matemáticas,
Crear imágenes, o dar explicaciones lógicas, o incluso dar consejos médicos, o simplemente mostrar lo emocionalmente inteligente que es.
Durante estas diversas pruebas, los modelos demuestran sus fortalezas y debilidades en diferentes áreas. Por ejemplo, mientras GPT-5 Se destaca en la deducción científica, pero se queda atrás de personajes como Géminis y Claude en su capacidad de adaptarse a nuevos conceptos.
Cada una de estas pruebas nos revela algo nuevo sobre los modelos de IA y son importantes para recordarnos qué herramientas son las mejores en diferentes escenarios. Sin embargo, a menudo falta una métrica: ¿qué modelos de IA ofrecen la mejor experiencia de usuario?
Sistema de clasificación humana
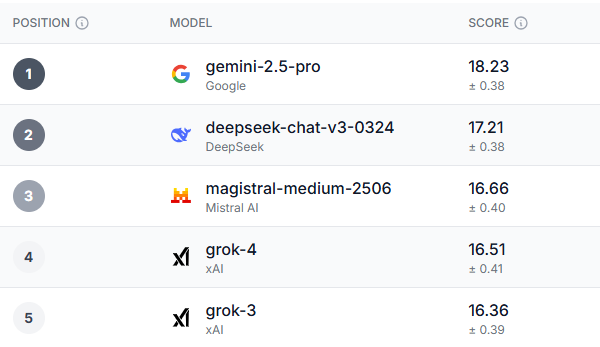
Una empresa tecnológica con sede en el Reino Unido llamada Prolific ha creado Una tabla de clasificación de IA llamada HumaineEn lugar de probar la capacidad de la IA para completar tareas, Prolific probó diferentes experiencias de usuario con estos modelos.
Al evaluar las experiencias de 21,352 personas con las herramientas, no solo pudieron encontrar un ganador general, sino que también pudieron desglosar los resultados por edad, ubicación (las pruebas se realizaron tanto en el Reino Unido como en los EE. UU.) y creencias políticas.
Esto incluye listados individuales para:
- Reino Unido: Grupos de edad
- Reino Unido: Raza
- Reino Unido: punto de vista político
- Estados Unidos: Grupos de edad
- Estados Unidos: Raza
- Estados Unidos: punto de vista político
El equipo hizo que cada participante interactuara con dos modelos de IA separados a modo de comparación y les pidió que brindaran comentarios sobre qué modelo funcionó mejor en cada interacción.
Esto dio como resultado un ganador general y una clasificación por desempeño, pero también clasificaciones separadas para el desempeño de tareas básicas y el razonamiento, así como un ganador por comunicación, resiliencia, confianza y ética.
¿Qué muestran los resultados?

Tras un análisis exhaustivo, surgió un claro ganador, no solo en la categoría de rendimiento general, sino en la mayoría de las subcategorías. El Gemini 2.5-Pro sobresalió en casi todos los parámetros de la prueba.
Los jóvenes de entre 18 y 34 años en el Reino Unido, los votantes demócratas y los mayores de 55 años en los EE. UU. coincidieron en que Géminis 2.5 Pro Es el mejor modelo en general. El único aspecto donde todos los grupos demográficos obtuvieron una puntuación superior a la de Gemini fue en confianza, ética y seguridad, y se trató de Grok-3, un hallazgo un tanto irónico dados algunos de los problemas de seguridad y ética que han enfrentado recientemente los modelos de IA.
Curiosamente, los tres modelos que surgieron después de Gemini son Deepseek, Magistral Le Chat y GrokAunque Deepseek alcanzó una gran popularidad a principios de este año, recientemente ha perdido protagonismo. Le Chat, por otro lado, es un chatbot menos popular, pero cuenta con una base de seguidores fieles.
¿Y dónde encaja el mundialmente famoso ChatGPT en todo esto? Está al final de la lista, en el octavo puesto, con el modelo GPT-4.1 mejor valorado. Peor aún es... Claude, donde en sus cuatro ediciones ocupó el undécimo y duodécimo puesto en la clasificación general.
Entonces ¿qué significa todo esto?
¿Significa esto que Gemini es el mejor chatbot con IA del mundo? ¿Significa que deberías descartar ChatGPT…? Bueno, no exactamente.
Estos resultados no reflejan necesariamente el rendimiento de estos modelos. Al probarlos con la mayoría de las demás métricas, las opciones que solemos ver en la parte superior son ChatGPT, Gemini, Claude y Grok.
Sin embargo, esta es una adición importante a estas pruebas. Nos ayuda a comprender mejor la IA desde la perspectiva de la experiencia humana. Por ejemplo, Le Chat no obtiene una puntuación alta en los parámetros estándar, pero a menudo se considera una excelente opción en términos de experiencia y fiabilidad.
Si bien el rendimiento de Anthropic y OpenAI no alcanzó este nivel en esta ronda de pruebas, Gemini y Grok obtuvieron otro buen resultado. Ambas compañías suelen obtener altas puntuaciones en los benchmarks estándar, y lo siguieron haciendo también en este caso.
Los comentarios están cerrados.