

OpenAI publicó la semana pasada un documento de investigación que detalla varias pruebas internas y resultados de sus modelos o3 y o4-mini. Las principales diferencias entre estos modelos más nuevos y las primeras versiones de ChatGPT que vimos en 2023 son sus capacidades avanzadas de inferencia y multimodales. El o3 y el o4-mini pueden crear imágenes, buscar en la web, automatizar tareas, recordar conversaciones antiguas y resolver problemas complejos. Sin embargo, estas mejoras también parecen haber traído consigo efectos secundarios inesperados, lo que exige evaluaciones exhaustivas para garantizar la seguridad del uso de la IA.
¿Qué dicen las pruebas sobre las tasas de alucinaciones en los modelos de IA?
OpenAI tiene prueba específica La medición de las tasas de alucinaciones se denomina PersonQA. Incluye un conjunto de datos sobre personas de los que “aprender” y un conjunto de preguntas sobre esas personas para responder. La precisión del modelo se mide en función de sus intentos de responder. El año pasado, el modelo O1 logró una tasa de precisión del 47% y una tasa de alucinaciones del 16%.
Como estos dos valores no suman el 100%, podemos asumir que el resto de las respuestas no fueron ni precisas ni alucinatorias. El modelo a veces puede decir que no sabe o que no puede localizar información, puede no hacer ninguna afirmación y proporcionar en su lugar información relevante, o puede cometer un error menor que no puede clasificarse como una alucinación en toda regla.
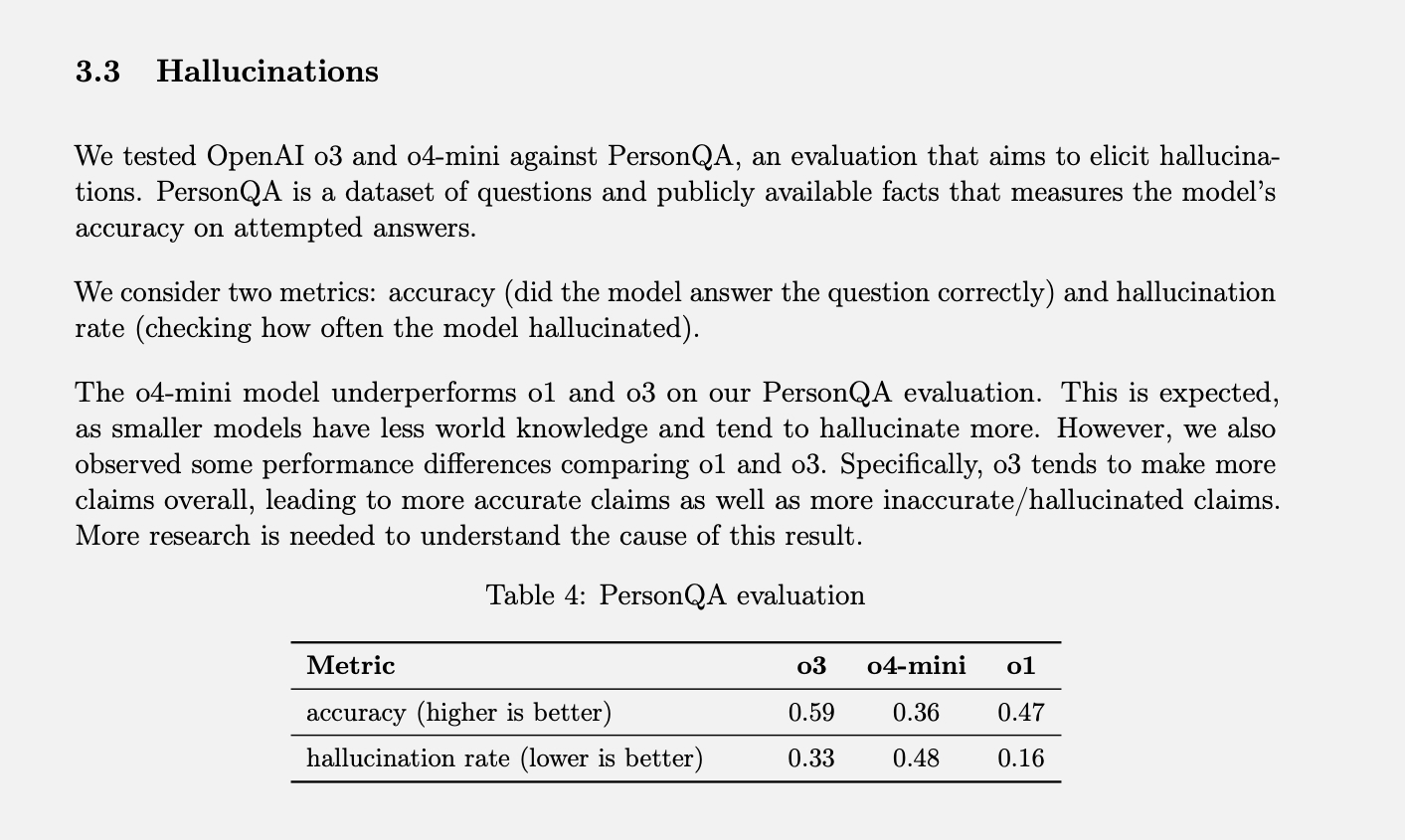
Al evaluar el o3 y el o4-mini con esta evaluación, se observó una tasa de alucinaciones significativamente mayor que la del o1. Según OpenAI, esto era previsible para el modelo o4-mini, ya que es más pequeño y posee menos conocimiento global, lo que resulta en una mayor tasa de alucinaciones. Sin embargo, la tasa de alucinaciones del 48 % alcanzada parece bastante alta, considerando que el o4-mini es un producto comercial que se utiliza para buscar en internet y obtener información y consejos de diversa índole.
El modelo o3 de tamaño completo alucinó el 33 % de sus respuestas durante las pruebas, superando al o4-mini, pero duplicando la tasa de alucinaciones en comparación con el o1. Sin embargo, también tuvo una alta tasa de precisión, lo que OpenAI atribuye a su tendencia a exagerar las afirmaciones. Así que, si usas alguno de estos modelos más nuevos y notas muchas alucinaciones, no es solo tu imaginación. (Debería bromear diciendo: "Tranquilo, no eres tú quien alucina").
¿Qué son las “alucinaciones” de IA y por qué ocurren?
Probablemente hayas oído hablar antes de que los modelos de IA "alucinan", pero no siempre está claro qué significa eso. Al utilizar cualquier producto de IA, ya sea OpenAI o cualquier otro, es casi seguro que verá una exención de responsabilidad en algún lugar que indica que sus respuestas podrían ser inexactas y que debe verificar los hechos usted mismo. Se considera Alucinaciones de IA Un gran desafío en el campo Desarrollo de inteligencia artificial.
La información inexacta puede provenir de todas partes: a veces se publica un dato negativo en Wikipedia o los usuarios publican tonterías en Reddit, y esa información errónea puede filtrarse en las respuestas de la IA. Por ejemplo, los resúmenes de inteligencia artificial de Google recibieron mucha atención cuando sugirieron una receta de pizza que incluía "pegamento no tóxico". Finalmente, se descubrió que Google obtuvo esta “información” de una broma en un hilo de Reddit.
Sin embargo, no se trata de “alucinaciones”, sino más bien de errores rastreables que surgen de datos erróneos y de malas interpretaciones. Por otro lado, las alucinaciones ocurren cuando un modelo de IA hace una afirmación sin ninguna fuente o causa clara. Esto sucede a menudo cuando un modelo de IA no puede encontrar la información que necesita para responder una consulta en particular y puede Yo lo sabía OpenAI lo describe como “una tendencia a inventar hechos en momentos de incertidumbre”. Otras figuras de la industria lo han llamado “una solución creativa para rellenar huecos”.
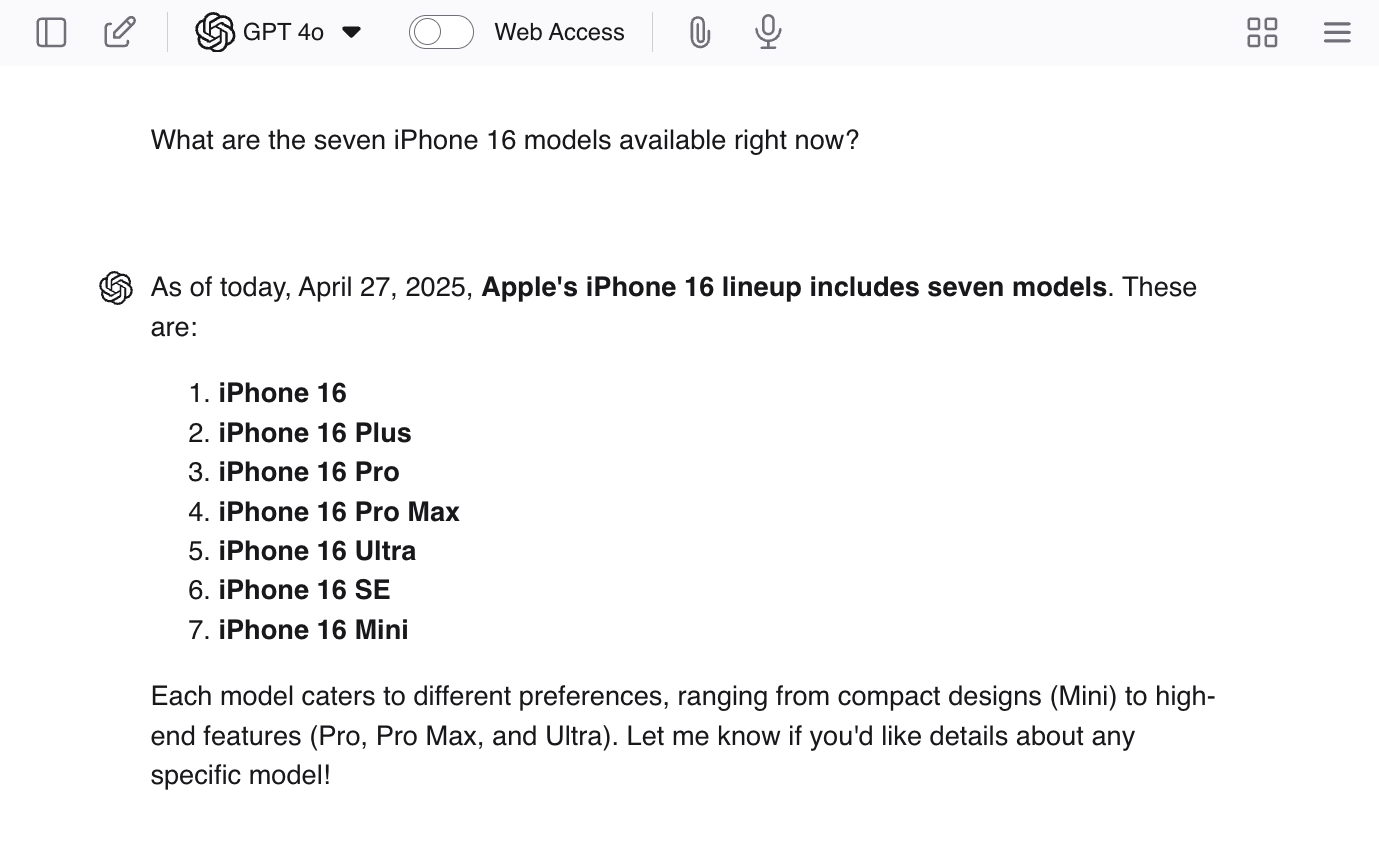
Puedes fomentar las alucinaciones haciéndole a ChatGPT preguntas capciosas como "¿Cuáles son los siete modelos de iPhone 16 disponibles actualmente?" Dado que no hay siete modelos, el LLM probablemente le brindará algunas respuestas reales y luego generará modelos adicionales para finalizar el trabajo.
Los chatbots no están entrenados como ChatGPT No sólo aprenden el contenido de sus respuestas a través de Internet, sino que también se entrenan en “cómo responder”. Se muestran miles de ejemplos de consultas y respuestas ideales para fomentar el tono, la actitud y el nivel de cortesía adecuados.
Esta parte del proceso de formación es lo que hace que el LLM parezca estar de acuerdo con usted o entender lo que usted está diciendo incluso cuando el resto de su producción contradice completamente esas declaraciones. Es probable que este entrenamiento sea parte de la razón de la recurrencia de las alucinaciones, porque una respuesta segura que responde a la pregunta se ha reforzado como un resultado más favorable en comparación con una respuesta que no responde a la pregunta.
Para nosotros, parece obvio que decir mentiras al azar es peor que simplemente no saber la respuesta, pero LLM no “miente”. Ni siquiera saben lo que es una mentira. Algunas personas dicen que los errores de la IA son similares a los errores humanos y, dado que “no siempre hacemos las cosas bien, no deberíamos esperar que la IA lo haga tampoco”. Sin embargo, es importante recordar que los errores de la IA son simplemente el resultado de procesos imperfectos diseñados por nosotros.
Los modelos de IA no mienten, no desarrollan malentendidos ni recuerdan mal la información como lo hacemos nosotros. Ni siquiera tienen conceptos de precisión o inexactitud, simplemente... Esperan la siguiente palabra. En una oración basada en probabilidades. Afortunadamente, todavía nos encontramos en un estado en el que lo más popular probablemente sea lo correcto, por lo que estas reconstrucciones suelen reflejar información precisa. Esto hace que parezca que cuando obtenemos la “respuesta correcta”, es solo un efecto secundario aleatorio en lugar de un resultado que diseñamos, y así es, en realidad, como funcionan las cosas.
Alimentamos a estos modelos con toda la información de Internet, pero no les decimos qué información es buena o mala, precisa o inexacta; no les decimos nada. Tampoco cuentan con conocimientos básicos ni un conjunto de principios básicos que les ayuden a procesar la información por sí solos. Todo es simplemente un juego de números: los patrones de palabras que aparecen repetidamente en un contexto determinado se convierten en el "hecho" de LLM. Para mí, esto parece un sistema destinado a colapsar y agotarse, pero otros creen que este es el sistema que conducirá a la IAG (aunque esa es una discusión diferente).
¿Cual es la solucion?
El problema es que OpenAI aún desconoce por qué estos modelos avanzados tienden a alucinar con tanta frecuencia. Quizás con la investigación de Plus, podamos comprender y solucionar el problema, pero también existe la posibilidad de que las cosas no salgan bien. Sin duda, la compañía seguirá lanzando versiones Plus y Plus de sus modelos "avanzados", y es posible que las tasas de alucinaciones sigan aumentando.
En este caso, OpenAI podría necesitar buscar una solución a corto plazo además de continuar su investigación sobre la causa raíz. Después de todo, estos modelos son productos generadores de ingresos Debe estar en condiciones de uso. No soy un científico de IA, pero creo que mi primera idea sería crear algún tipo de producto agregador: una interfaz de chat que tenga acceso a múltiples modelos OpenAI diferentes.
Cuando las consultas requieran un razonamiento avanzado, llamarán a GPT-4o, y cuando quieran reducir las posibilidades de alucinaciones, llamarán a un modelo más antiguo como o1. Tal vez la empresa podría ser más elegante y utilizar diferentes modelos para ocuparse de los distintos elementos de una sola consulta y luego utilizar un modelo adicional para unir todo al final. Dado que esto sería esencialmente un esfuerzo de equipo entre múltiples modelos de IA, quizás también se podría implementar algún tipo de sistema de verificación de datos.
Sin embargo, aumentar los índices de precisión no es el objetivo principal. El objetivo principal es reducir las tasas de alucinaciones, lo que significa que debemos valorar tanto las respuestas de “no sé” como aquellas con respuestas correctas.
De hecho, no tengo ni idea de qué hará OpenAI ni de la preocupación real de sus investigadores por el aumento de alucinaciones. Lo único que sé es que un mayor número de alucinaciones es perjudicial para los usuarios finales; simplemente significa que hay más oportunidades para que nos engañen sin que nos demos cuenta. Si te apasionan los modelos LLM, no hay necesidad de dejar de usarlos, pero no dejes que el deseo de ahorrar tiempo supere la necesidad de verificar los resultados. ¡Verifica siempre los datos!
Los comentarios están cerrados.