

En los últimos años, los Modelos de Lenguaje Grandes (LLM) se han vuelto cada vez más populares gracias a su capacidad para generar texto con una estructura similar a la humana y facilitar diversas tareas. No todos los modelos son de código abierto, pero casi todas las grandes empresas tecnológicas tienen una versión que los usuarios pueden descargar y ejecutar.

Ejecutar estos modelos localmente en tu Mac puede ser beneficioso tanto por razones de privacidad como de costo. En este artículo, exploraremos cómo instalar y ejecutar LLM usando OllamaEs una herramienta poderosa para desarrolladores y usuarios novatos, y discutiremos algunas herramientas de interfaz gráfica de usuario que pueden simplificar el proceso para aquellos que prefieren no usar la Terminal macOS.
De esta manera, puede acceder a las últimas plantillas de texto impulsadas por IA de [Google], [Microsoft], [Meta] y otras empresas de IA como [Mistral] y [DeepSeek].
Entendiendo los LLM: ¿Qué significan los parámetros?
Antes de sumergirnos en el proceso de instalación, aclaremos qué significan números como “7B"O"14BAl referirse a los LLM, estos números representan el tamaño del modelo en términos de los maestros (En miles de millones), que son esencialmente “manijas e interruptores” que se ajustan con precisión durante el entrenamiento.
Un mayor número de parámetros permite al modelo capturar patrones y relaciones más complejos en el lenguaje, lo que potencialmente mejora el rendimiento. Sin embargo, es importante destacar que tener más parámetros no siempre garantiza mejores resultados; la calidad de los datos de entrenamiento y los recursos computacionales disponibles para el modelo también juegan un papel importante.
Requisitos del sistema
Necesitarás asegurarte de que tu [Mac] tenga al menos las siguientes especificaciones:
- macOS 10.15 o posterior (se recomienda macOS 13 o posterior)
- Al menos 8 GB de RAM (se recomiendan 16 GB o más)
- 10 GB de espacio de almacenamiento libre (el mínimo requerido para los modelos más pequeños; los modelos más avanzados con un número máximo de parámetros requieren aproximadamente 700 GB)
- Procesador multinúcleo [Intel] o procesador [Apple Silicon] (preferiblemente M2 o superior)
Instalar Ollama
Ollama Es una herramienta de código abierto que permite ejecutar LLM directamente en el equipo local. Para empezar, siga estos pasos:
- Descargar Ollama: Visite el sitio web Ollama Descarga la versión para macOS. También puedes usar [Homebrew] para instalarla ejecutando
brew install ollamaEn tu terminal.

- Instalar OllamaSi descargaste el instalador, haz doble clic en él y sigue el asistente de instalación. Si usas Homebrew, ve al paso 4.

- El siguiente paso para el instalador es simplemente hacer clic en el botón. تثبيتQue le pedirá su contraseña de administrador.
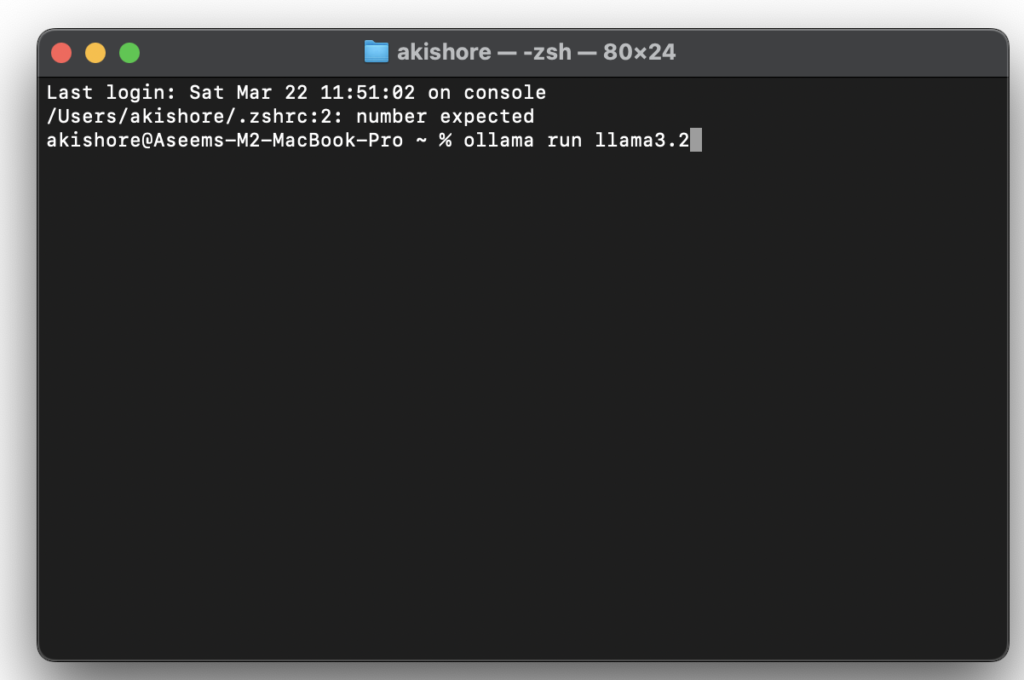
- Corre OllamaAbra una ventana de terminal e inicie Ollama como un servicio usando el comando
brew services start ollamaEsto hará que Ollama esté disponible en la direcciónhttp://localhost:11434/. - Descargue y ejecute el modeloUtilice el comando
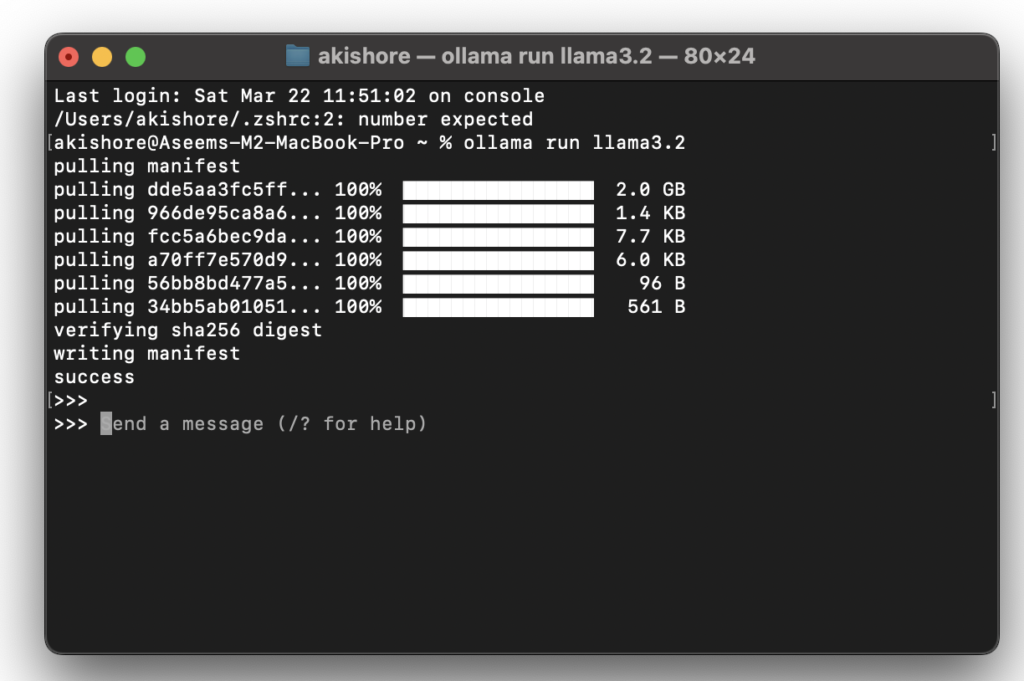
ollama pull <model-name>Para descargar una plantilla, entonces el comandoollama run <model-name>Para ejecutarlo. Por ejemplo, para ejecutar un modelo DeepSeek-R1, usa el comandoollama pull deepseek-r1Seguido de la ordenollama run deepseek-r1. - Para descargar una versión más grande de la plantilla, simplemente añada dos puntos verticales seguidos del tamaño. Por ejemplo, para descargar una plantilla Búsqueda profunda 14BUsarás el comando ollama ejecuta deepseek-r1:14bEn el sitio web de Ollama, puede hacer clic en cualquiera de los formularios y se le mostrarán todos los diferentes comandos para cada versión.
Puede encontrar la lista completa de Modelos Ollama Aquí. También puedes usar el segundo comando, como se describió anteriormente. Si aún no está instalado, primero extraerá el formulario y luego lo ejecutará.
Ahora que ves las tres flechas en ángulo recto (>>>), puedes comenzar a escribir comandos en el formulario.
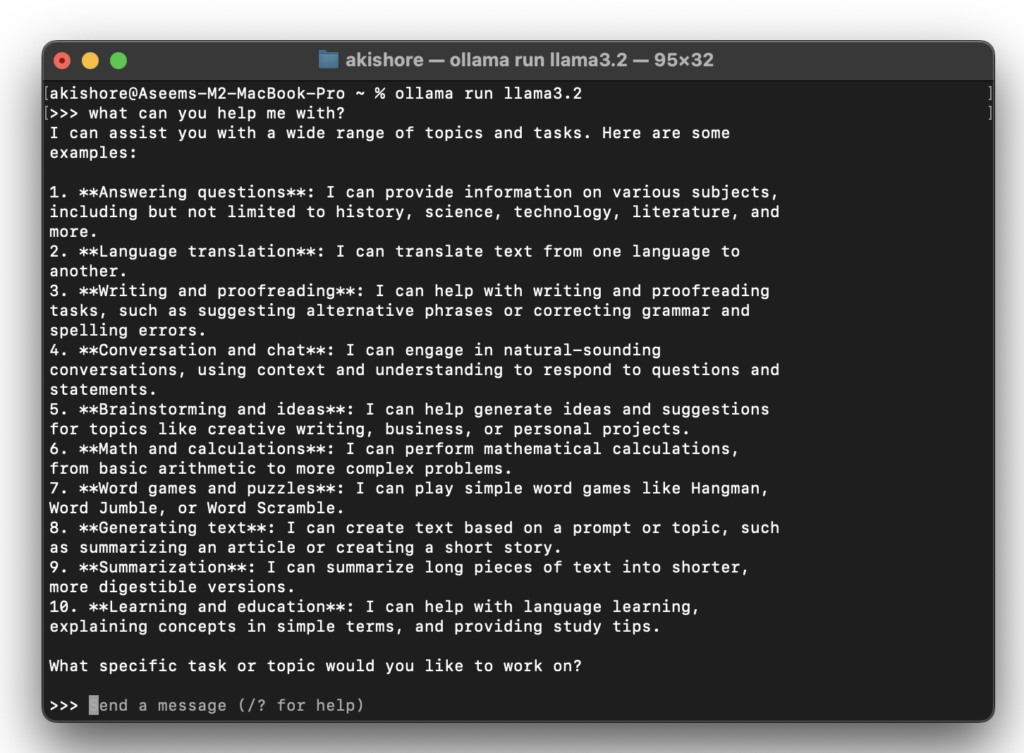
¡Listo! Ahora puedes interactuar localmente con tu LLM en IA sin preocuparte por costos, uso excesivo ni que otros lean lo que escribes. Esto es ideal si tienes temas delicados o personales que te gustaría discutir con un LLM en IA, pero no quieres que una gran empresa tecnológica lea tus pensamientos.
Uso de herramientas de interfaz gráfica de usuario con Ollama
Si bien Ollama es potente y eficiente para desarrolladores, algunos usuarios podrían preferir una interfaz gráfica de usuario (GUI) para interactuar con LLM. Aquí hay algunas herramientas que pueden proporcionar una interfaz gráfica de usuario para Ollama:
-
-
- Interfaz gráfica de usuario de OllamaEsta es una aplicación gratuita y de código abierto para usuarios de macOS, desarrollada con SwiftUI. Ofrece una interfaz atractiva y es una excelente opción para quienes desean acceder a los formularios LLM localmente sin usar una terminal.
- Interfaz de usuario de OllamaUna interfaz de usuario web sencilla basada en HTML que permite definir formularios e interactuar con ellos directamente en el navegador. También incluye una extensión de Chrome para facilitar el acceso.
- IA de ChatboxEsta es la opción más sencilla para principiantes y te explicaré cómo usarla a continuación. Ten en cuenta que no necesitas el servicio Chatbox AI, que es una suscripción que ofrecen para acceder a todas las plantillas LLM sin tener que instalar Ollama.
-
Para utilizar la mejor interfaz de IA de Chatbox, vaya a página de descarga Obtén la versión específica para tu Mac.
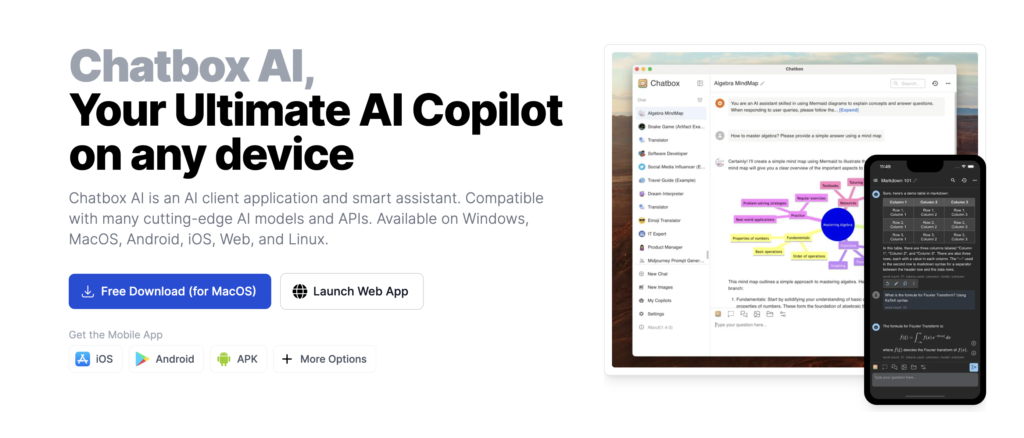
A continuación, abra el instalador y ejecute el programa. En la primera pantalla, aparecerá una ventana emergente que le preguntará cómo usar Chatbox AI.
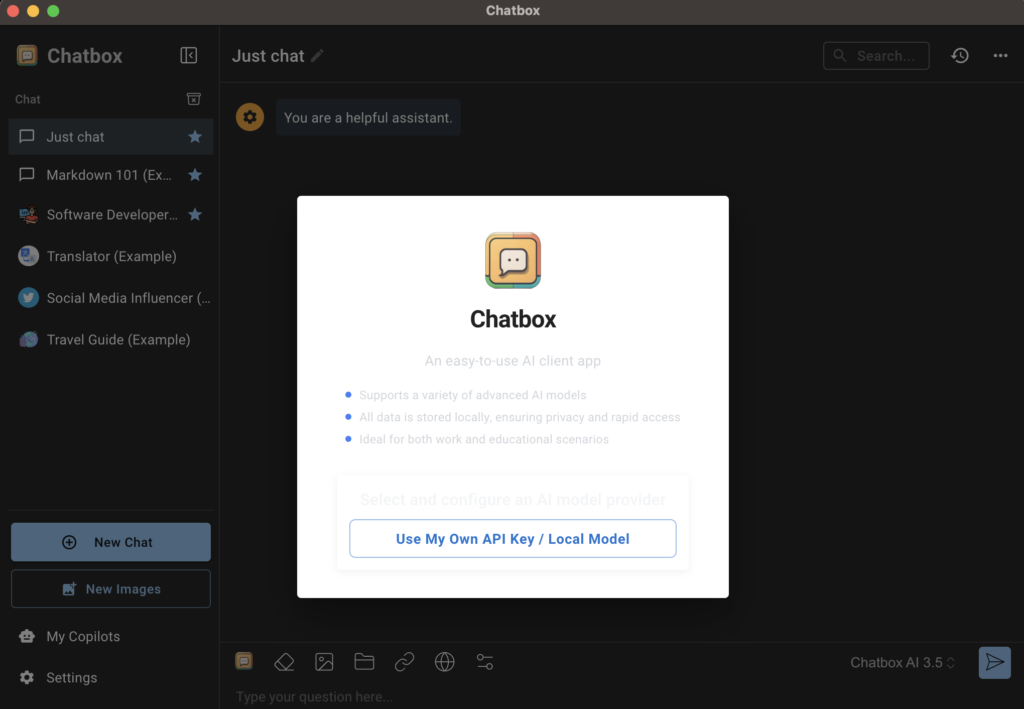
Necesitarás hacer clic en el botón Usar mi propia clave API/modelo local.
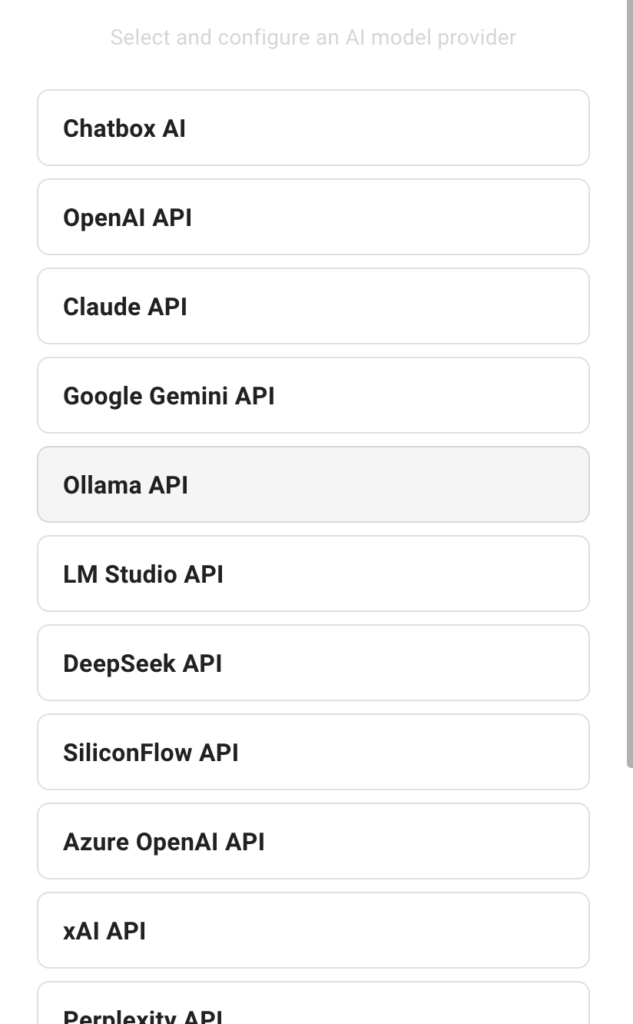
A continuación, toque API de Ollama Como proveedor de modelos de inteligencia artificial.
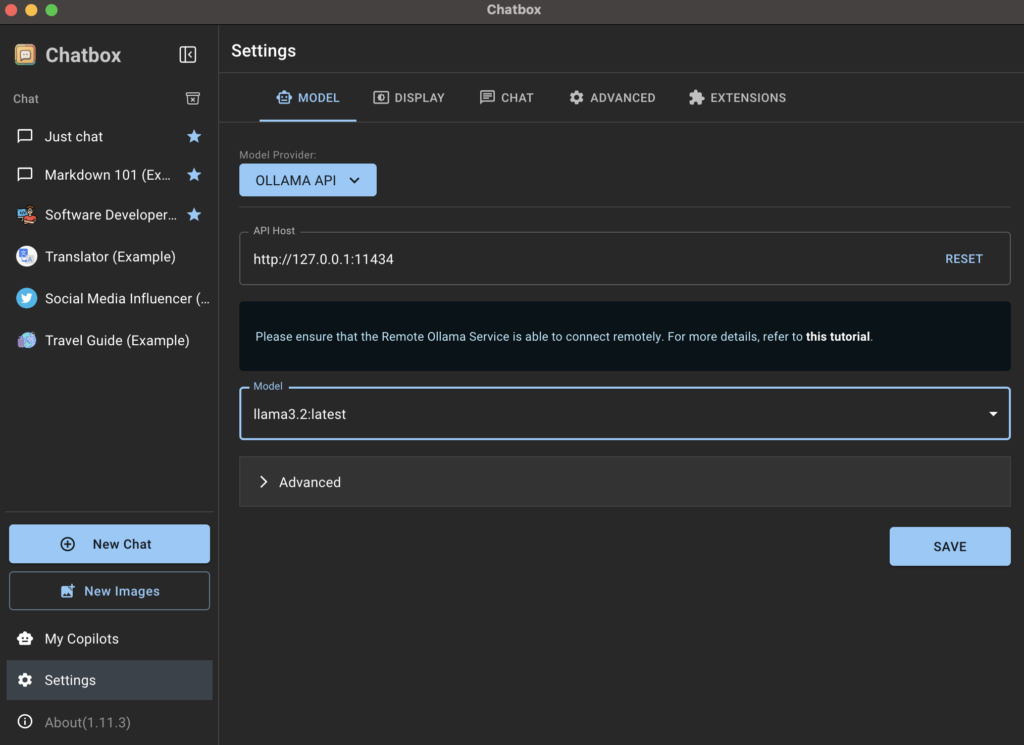
Chatbox AI debería detectar automáticamente que Ollama se está ejecutando y configurar el host API a su valor predeterminado, que es dirección IP de bucle invertido y número de puerto 11434No necesitas cambiar nada aquí. Dentro del formulario, deberías ver los formularios que instalaste previamente usando la Terminal. En mi caso, es el formulario. llamas 3.2.
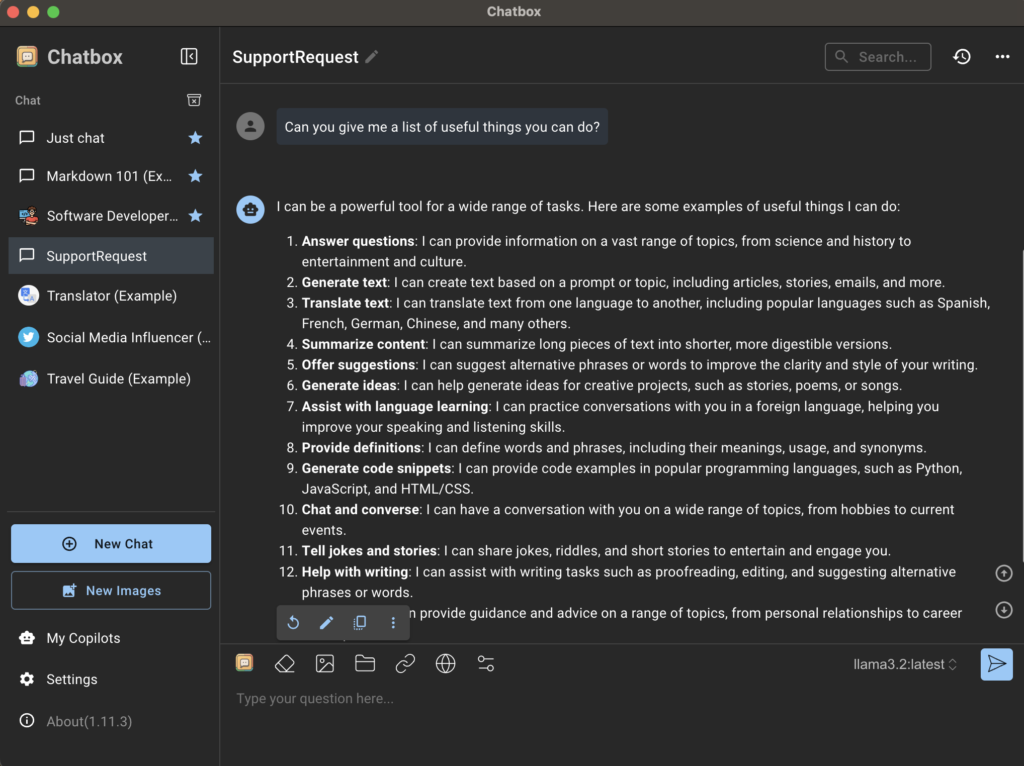
Para regresar a la página de inicio de la aplicación, haga clic en Solo conversa O Nueva conversación Asegúrate de seleccionar la plantilla correcta en la esquina inferior derecha. Puedes cambiarla en cualquier momento, pero te recomiendo crear un chat nuevo para cada plantilla que uses para que puedas ver fácilmente las diferencias.
Herramientas alternativas para ejecutar modelos LLM localmente
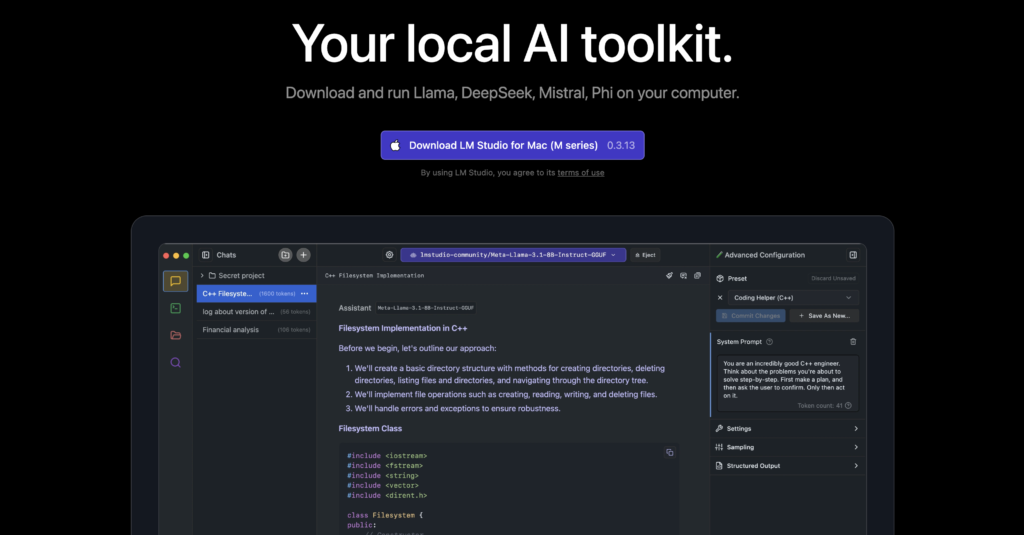
Si estás buscando alternativas a Ollama o prefieres una experiencia más fácil de usar desde el principio, entonces Estudio LM Es otra excelente opción. Ofrece una interfaz intuitiva para explorar y usar diversos modelos de IA, lo que permite descargarlos y ejecutarlos fácilmente. LM Studio está disponible para Linux, Mac y Windows y ofrece funciones como la personalización de los parámetros del modelo y el historial de chat. Actualmente es gratuito, por lo que lo recomiendo en lugar del servicio de suscripción Chatbox AI.
Conclusión
Ejecutar modelos de lenguaje grandes (LLM) localmente en tu Mac será importante para quienes buscan un mayor control sobre sus aplicaciones de IA y priorizar la privacidad de los datos. Con herramientas como Ollama y las interfaces gráficas mencionadas, que facilitan la integración de los LLM en tu flujo de trabajo, puedes liberar de forma segura un nuevo potencial de productividad y creatividad.
Sin embargo, iniciar una implementación local de LLM requiere comprender los parámetros y cómo afectan el rendimiento de estos modelos en su equipo. La mejor manera de aprender esto es experimentar con diferentes modelos para ver cuáles ofrecen los mejores resultados. Una vez que comprenda este concepto, podrá tomar mejores decisiones sobre qué modelos usar y cómo optimizar su rendimiento para satisfacer sus necesidades específicas.
Los comentarios están cerrados.